
Metascience Since 2012: A Personal History

This essay is a personal history of the $60+ million I allocated to metascience starting in 2012 while working for the Arnold Foundation (now Arnold Ventures).
Keep reading if you want to know:
How the Center for Open Science started
How I accidentally up working with the John Oliver show
What kept PubPeer from going under in 2014
How a new set of data standards in neuroimaging arose
How a future-Nobel economist got started with a new education research organization
How the most widely-adopted set of journal standards came about
Why so many journals are offering registered reports
How writing about ideas on Twitter could fortuitously lead to a multi-million grant
Why we should reform graduate education in quantitative disciplines so as to include published replications
When meetings are useful (or not)
Why we need a new federal data infrastructure
I included lots of pointed commentary throughout, on issues like how to identify talent, how government funding should work, and how private philanthropy can be more effective. The conclusion is particularly critical of current grantmaking practices, so keep reading (or else skip ahead).
Introduction
A decade ago, not many folks talked about “metascience” or related issues like scientific replicability. Those who did were often criticized for ruffling too many feathers. After all, why go to the trouble of mentioning that some fields weren’t reproducible or high-quality? Top professors at Harvard and Princeton even accused their own colleagues of being “methodological terrorists” and the like, just for supporting replication and high-quality statistics.
The situation seems far different today. Preregistration has become much more common across many fields; the American Economic Association now employs a whole team of people to rerun the data and code from every published article; national policymakers at NIH and the White House have launched numerous initiatives on reproducibility and open science; and just recently, the National Academies hosted the Metascience 2023 conference.
How did we get from there to here? In significant part, it was because of “metascience entrepreneurs,” to use a term from a brilliant monograph by Michael Nielsen and Kanjun Qiu. Such entrepreneurs included folks like Brian Nosek of the Center for Open Science, and many more.
But if there were metascience entrepreneurs, I played a significant part as a metascience venture capitalist—not the only one, but the most active. While I worked at what was initially known as the Laura and John Arnold Foundation (now publicly known as Arnold Ventures), I funded some of the most prominent metascience entrepreneurs of the past 11 years, and often was an active participant in their work. The grants I made totaled over $60 million dollars. All of that was thanks to the approval of Laura and John Arnold themselves (John made several billion dollars running a hedge fund, and they retired at 38 with the intention of giving away 90+% of their wealth).
In the past few months, two people in the metascience world independently asked if I had ever written up my perspective on being a metascience VC. This essay was the result. I’ve done my best not to betray any confidentialities or to talk about anyone at Arnold Ventures other than myself. I have run this essay by many people (including John Arnold) to make sure my memory was correct. Any errors or matters of opinion are mine alone.
The Origin Story: How the Arnold Foundation Got Involved in Metascience
As I have often said in public speeches, I trace the Arnold Foundation’s interest in metascience to a conversation that I had with John Arnold in mid-2012.
I had started working as the foundation’s first director of research a few months prior. John Arnold and I had a conference call with Jim Manzi, the author of a widely-heralded book on evidence-based policy.
I don’t remember much about the call itself (other than that Manzi was skeptical that a foundation could do much to promote evidence-based policy), but I do remember what happened afterwards. John Arnold asked me if I had seen a then-recent story about a psychology professor at Yale (John Bargh) whose work wouldn’t replicate and who was extraordinarily upset about it.
As it turned out, I had seen the exact same story in the news. It was quite the tempest in a teapot. Bargh had accused the folks replicating his work of being empty-headed, while Nobel Laureate Daniel Kahneman eventually jumped in to say that the “train wreck” in psychological science could be avoided only by doing more replications.
In any event, John Arnold and I had an energetic conversation about what it meant for the prospect of evidence-based policy if much of the “evidence” might not, in fact, be true or replicable (and still other evidence remained unpublished).
I began a more systematic investigation of the issue. It turned out that across many different fields, highly-qualified folks had occasionally gotten up the courage to write papers that said something along the lines of, “Our field is publishing way too many positive results, because of how biased our methods are, and you basically can’t trust our field.” And there was the famous 2005 article from John Ioannidis: “Why Most Published Research Findings Are False.” To be sure, the Ioannidis article was just an estimate based on assumptions about statistical power, likely effect sizes, and research flexibility, but to me, it still made a decent case that research standards were so low that the academic literature was often indistinguishable from noise.
That’s a huge problem for evidence-based policy! If your goal in philanthropy is to give money to evidence-based programs in everything from criminal justice to education to poverty reduction, what if the “evidence” isn’t actually very good? After all, scholars can cherrypick the results in the course of doing a study, and then journals can cherrypick what to publish at all. At the end of the day, it’s hard to know if the published literature actually represents a fair-minded and evidence-based view.
As a result, the Arnolds asked me to start thinking about how to fix the problems of publication bias, cherrypicking, misuse of statistics, inaccurate reporting, and more.
These aren’t easy problems to solve, not by any means. Yes, there are many technical solutions that are on offer, but mere technical solutions don’t address the fact that scholars still have a huge incentive to come up with positive and exciting results.
But I had to start somewhere. So I started with what I knew . . .
Brian Nosek and the Birth of the Center for Open Science
I had already come across Brian Nosek after an April 2012 article in the Chronicle of Higher Education titled “Is Psychology About to Come Undone?” I was impressed by his efforts to work on improving standards in psychology. To be sure, I don’t normally remember what articles I saw in a specific month over 11 years ago, but in searching back through my Gmail, I saw that I had emailed Peter Attia (who recently published an excellent book!) and Gary Taubes about this article at the time.
Which could lead to another long story in itself: the Arnolds were interested in funding innovative nutrition research, and I advised them on setting up the Nutrition Science Initiative led by Attia and Taubes (here’s an article in Wired from 2014). As of early 2012, I was talking with Attia and Taubes about how to improve nutrition science, and wondered what they thought of Nosek’s parallel efforts in psychology.
In any event, as of summer 2012, I had a new charge to look into scientific integrity more broadly. I liked Nosek’s idea of running psychology replication experiments, his efforts to mentor a then-graduate student (Jeff Spies) in creating the Open Science Framework software, and in particular, a pair of articles titled Scientific Utopia I and Scientific Utopia II.
The first article laid out a new vision for scientific communication: “(1) full embrace of digital communication, (2) open access to all published research, (3) disentangling publication from evaluation, (4) breaking the ‘one article, one journal’ model with a grading system for evaluation and diversified dissemination outlets, (5) publishing peer review, and, (6) allowing open, continuous peer review.” The second article focused on “restructuring incentives and practices to promote truth over publishability.”
Even with the benefit of hindsight, I’m still impressed with the vision that Nosek and his co-authors laid out. One of the first things I remember doing was setting up a call with Brian. I then invited him out to Houston to meet with the Arnolds and the then-president of the Arnold Foundation (Denis).
At that point, no one knew where any of this would lead. As Brian himself has said, his goal at that point was to get us to fund a post-doc position at maybe $50k a year.
For my part, I thought that if you find smart people doing great things in their spare time, empowering them with additional capital is a good bet. I continue to think that principle is true, whether in philanthropy, business, or science.
After the meeting, Denis said that he and Arnolds had loved Brian’s vision and ideas. He said something like, “Can’t we get him to leave the University of Virginia and do his own thing full-time?” Out of that conversation, we came up with the name “Center for Open Science.” I went back to Brian and said that the Arnolds liked his vision, and asked if he would be willing to start up a “Center for Open Science”? Brian wasn’t hard to persuade, as the offer was consistent with his vision for science, yet far beyond what he had hoped to ask for.
He and I worked together on a proposal. In fact, in my Google Docs, I still have a draft from November 2012 titled, “Center for Open Science: Scenario Planning.” The introduction and goal:
“We aim to promote open science, evaluate or improve reproducibility of scientific findings, and improve the alignment of scientific practices to scientific values. Funding will ensure, accelerate, and broaden impact of our projects. All projects are interdisciplinary or are models to replicate across disciplines. The Center for Open Science (COS) will support innovation, open practices, and reproducibility in the service of knowledge-building. COS would have significant visibility to advance an open science agenda; establish and disseminate open science best practices; coordinate and negotiate with funders, journals, and IRBs for open science principles; support and manage open infrastructure; connect siloed communities particularly across disciplines; and, support open science research objectives.”
More than 10 years later, that’s still a fairly good description of what COS has been able to accomplish.
As of September 2013, there was a Google doc that included the following:
Mission
COS aims to increase openness, integrity, and reproducibility of scientific research.
Openness and reproducibility are core scientific values because science is a distributed, non-hierarchical culture for accumulating knowledge. No individual is the arbiter of truth. Knowledge accumulates by sharing information and independently reproducing results. Ironically, the reward structure for scientists does not provide incentives for individuals to pursue openness and reproducibility. As a consequence, they are not common practices. We will nudge incentives to align scientific practices with scientific values.
Summary of Implementation Objectives
1. Increase prevalence of scientific values - openness, reproducibility - in scientific practice2. Develop and maintain infrastructure for documentation, archiving, sharing, and registering research materials
3. Join infrastructures to support the entire scientific workflow in a common framework
4. Foster an interdisciplinary community of open source developers, scientists, and organizations
5. Adjust incentives to make “getting it right” more competitive with “getting it published”
6. Make all academic research discoverable and accessible
Not bad. I eventually was satisfied that the proposal was worth bringing back to the Arnolds, and asking for $5.25 million. That’s what we gave Brian as the first of several large operational grants—$5 million was designated for operational costs for running the Center for Open Science for the first three years, and $250k was for completing 100 psychology replication experiments.
We were off to the races.
Interlude
From this point forward, I won’t narrate all of the grants and activities chronologically, but according to broader themes that are admittedly a bit retrofitted. Specifically, I’m now a fan of the pyramid of social change that Brian Nosek has written and talked about for a few years:
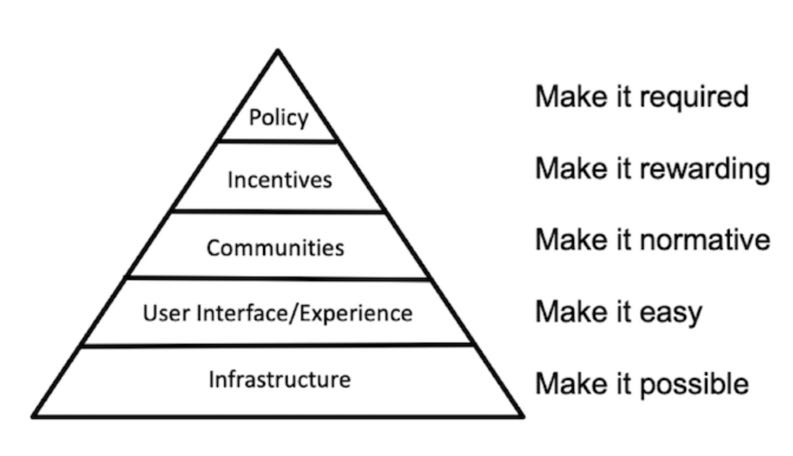
In other words, if you want scientists to change their behavior by sharing more data, you need to start at the bottom by making it possible to share data (i.e., by building data repositories). Then try to make it easier and more streamlined, so that sharing data isn’t a huge burden. And so on, up the pyramid.
You can’t start at the top of the pyramid (“make it required”) if the other components aren’t there first. For one thing, no one is going to vote for a journal or funder policy to mandate data sharing if it isn’t even possible. Getting buy-in for such a policy would require work to make data sharing not just possible, but more normative and rewarding within a field.
That said, I might add another layer at the bottom of the pyramid: “Raise awareness of the problem.” For example, doing meta-research on the extent of publication bias or the rate of replication can make entire fields aware that they have a problem in the first place—before that, they aren’t as interested in potential remedies for improving research behaviors.
The rest of this piece will be organized accordingly:
Raise Awareness: fundamental research on the extent of irreproducibility;
Make It Possible and Make It Easy: the development of software, databases, and other tools to help improve scientific practices;
Make It Normative: journalists and websites that called out problematic research, and better standards/guidelines/ratings related to research quality and/or transparency;
Make It Rewarding: community-building efforts and new journal formats
Make It Required: organizations that worked on policy and advocacy.
Disclaimer: As applied to Arnold grantmaking in hindsight, these categories aren’t comprehensive or mutually exclusive, and are somewhat retrofitted. They won’t be a perfect fit.
I. Raise Awareness Via Fundamental Research
The Meta-Research Innovation Center at Stanford (METRICS)
Around the 2012-13 time frame, I read about Dustin Moskovitz (co-founder of Facebook) and his partner Cari Tuna (it was something akin to this article from 2014), and their ambitions to engage in effective philanthropy. I asked John Arnold if he knew them, or how to get in touch with them. I ended up being redirected to Holden Karnofsky and Alexander Berger, who at the time worked at GiveWell (and since helped launch and run Open Philanthropy).
It turned out that they had been tentatively exploring metascience as well. They introduced me to Steve Goodman and John Ioannidis at Stanford, who had been thinking about the possibility of a center at Stanford focused on meta-research. Goodman sent along a 2-page (or so) document with the general idea, and I worked with him to produce a longer proposal.
My memory is no match for what Holden wrote at the time (more funders should do this while memories are still fresh!):
In 2012, we investigated the US Cochrane Center, in line with the then-high priority we placed on meta-research. As part of our investigation, we were connected – through our network – to Dr. Steven Goodman, who discussed Cochrane with us (notes). We also asked him about other underfunded areas in medical research, and among others he mentioned the idea of “assessing or improving the quality of evidence in the medical literature” and the idea of establishing a center for such work.
During our follow-up email exchange with Dr. Goodman, we mentioned that we were thinking of meta-research in general as a high priority, and sent him a link to our standing thoughts on the subject. He responded, “I didn’t know of your specific interest in meta-research and open science … Further developing the science and policy responses to challenges to the integrity of the medical literature is also the raison d’etre of the center I cursorily outlined, which is hard to describe to folks who don’t really know the area; I didn’t realize how far down that road you were.” He mentioned that he could send along a short proposal, and we said we’d like to see it.
At the same time, we were in informal conversations with Stuart Buck at the Laura and John Arnold Foundation (LJAF) about the general topic of meta-research. LJAF had expressed enthusiasm over the idea of the Center for Open Science (which it now supports), and generally seemed interested in the topic of reproducibility in the social sciences. I asked Stuart whether he would be interested in doing some funding related to the field of medicine as well, and in reviewing a proposal in that area that I thought looked quite promising. He said yes, and (after checking with Dr. Goodman) I sent along the proposal.
From that point on, LJAF followed its own process, though we stayed posted on the progress, reviewed a more fleshed-out proposal, shared our informal thoughts with LJAF, and joined (by videoconference) a meeting between LJAF staff and Drs. Ioannidis and Goodman.
Following the meeting with Drs. Ioannidis and Goodman, we told Stuart that we would consider providing a modest amount of co-funding (~10%) for the initial needs of METRICS. He said this wouldn’t be necessary as LJAF planned to provide the initial funding.
We (at the Arnold Foundation) ended up committing some $4.9 million dollars to launch the Meta-Research Innovation Center at Stanford, or METRICS. The goal was to produce more research (along with conferences, reports, etc.) on how to improve research quality in biomedicine, and to train the next generation of scholars in this field. METRICS did that in spades: they and their associated scholars published hundreds of papers on meta-science (mostly in biomedicine), and were able to hire quite a few postdocs to help create a future generation of scholars who focus on meta-science.
In 2015, METRICS hosted an international conference on meta-research that was well-attended by many disciplinary leaders. The journalist Christie Aschwanden was there, and she went around ambushing the attendees (including me) by asking politely, “I’m a journalist, would you mind answering a few questions on video?,” and then following that with, “In layman’s terms, can you explain what is a p-value?” The result was a hilarious “educational” video and article, still available here. I was singled out as the one person with the “most straightforward explanation” of a p-value, but I did have an advantage — thanks to a job where I had to explain research issues on a daily basis to other foundation employees with little research background, I was already in the habit of boiling down complicated concepts.
Steve Goodman has continued to do good work at Stanford, and is leading the Stanford Program on Research Rigor and Reproducibility (SPORR), a wide-ranging program whose goal is to “maximize the scientific value of all research performed in the Stanford School of Medicine.” SPORR now hands out several awards a year for Stanford affiliates who have taken significant steps to improve research rigor or reproducibility that can be used or modeled by others. It has also successfully incorporated those considerations into Stanford medical school’s promotion process and is working with leadership on institutional metrics for informative research.
The goal is to create “culture change” within Stanford and as a model for other academic institutions, so that good science practices are rewarded and encouraged by university officials (rather than just adding more publications to one’s CV). SPORR is arguably the best school-wide program in this regard, and it should be a model for other colleges and universities.
Bringing Ben Goldacre to Oxford
In the early 2010s, Ben Goldacre was both a practicing doctor in the UK and a professional advocate as to clinical trial transparency. He co-founded an EU-wide campaign called AllTrials on clinical trial transparency; wrote the book Bad Pharma (which both John Arnold and I read at the time); and wrote a nice essay on using randomized trials in education.
As I mentioned above, when someone is doing all of this in his spare time, a good bet would be to use philanthropy (or investment, depending on the sector) to enable that person to do greater things.
I reached out to Ben Goldacre in late 2013 or early 2014 (the timing is a bit unclear in my memory). I ended up sending the Arnolds an email titled, “The ‘Set Ben Goldacre Free’ Grant,” or something close to it.
My pitch was simple: We should enable Goldacre to pursue his many ideas as to data and evidence-based medicine, rather than being forced to do so in his spare time while working as a doctor by day.
I asked Goldacre if we could set him up with a university-based center or appointment. Unlike Brian Nosek, it took quite a bit of argument in this case. Goldacre was in the middle of buying a house in London. He wasn’t sure he could find such a good deal again, and he wanted to be very certain of our intentions before he backed out of the London house and moved anywhere else, such as Oxford (which itself was uncertain!). I eventually convinced him that the Arnold Foundation was good for its word, and that it was worth the move. We worked out the details with Oxford, and Arnold made a 5-year grant of $1.24 million in 2014.
Since then, Goldacre has thrived at Oxford. He spearheaded the TrialsTracker Project (which tracks which clinical trials have abided by legal obligations to report their results), and the COMPARE Project (which systematically looked at every trial published in the top 5 medical journals over a several-month period).
The latter’s findings were remarkable: out of 67 trials reviewed, only nine were perfect in their reporting. The other 58 had a collective 357 new outcomes “silently added” and 354 outcomes not reported at all (despite having been declared in advance). This is an indictment of the medical literature and of the ideal that clinical trials should register in advance and then report fully when done. Notably, the New England Journal of Medicine’s late John Jarcho said in 2017 that this project “has made NEJM more sensitive to the real problem of outcome switching.”
But it was an amazingly tedious project: while in the middle of all this work checking trial outcomes, Goldacre told me, “I rue the day I ever said I would do this.” It’s no wonder that hardly anyone else ever does this sort of work, and medical journals (among others) need better and more automated ways to check whether a publication is consistent with (or even contradicts) its registration, protocol, or statistical analysis plan.
Goldacre’s lab is now called the Bennet Institute for Applied Data Science, after a subsequent donor. The Institute maintains the OpenSafely project, which offers researchers access to well-curated medical records from 58 million people across the entire UK, as well as Open Prescribing, which does the same for prescription data. These efforts have led to many publications, particularly during Covid.
OpenSafely is especially interesting: despite the highly private nature of health data, Goldacre created a system in which “users are blocked from directly viewing the raw patient data or the research ready datasets, but still write code as if they were in a live data environment.” Instead, “the data management tools used to produce their research-ready datasets also produce simulated, randomly generated ‘dummy data’ that has the same structure as the real data, but none of the disclosive risks.”
Oxford professor Dorothy Bishop calls it a “phenomenal solution for using public data.” I think that federal and state governments in the US should do more to create similarly streamlined ways for researchers to easily analyze private data.
Goldacre recently gave his inaugural professorial lecture as the first Bennett Professor of Evidence Based Medicine in the Nuffield Department of Primary Care Health Sciences at Oxford. (The lecture is a tour-de-force; do watch it.) I’m pleased to have helped Goldacre along this path.
Open Trials
A significant problem with clinical trials, so it seemed to me, was that if a patient or doctor wanted to know the full spectrum of information about a drug or a trial, it required an enormous amount of effort and insider knowledge to track down. For example, you’d have to know:
How to search the medical literature,
How to look up trials on ClinicalTrials.gov,
How to check the FDA approval package (which is such a cumbersome process that the British Medical Journal once literally published an entire article with instructions on how to access FDA data),
How to check for whether the European Medicines Agency had any additional information, and more.
It was literally impossible to find the whole set of information about any drug or treatment in one place.
So, an idea I discussed with Ben Goldacre was creating a database/website that would pull in information about drugs from all of those places and more. If you were curious about tamoxifen (the cancer drug) or paroxetine (the antidepressant), you’d be able to see the entire spectrum of all scholarly and regulatory information ever produced on that drug.
I ended up making a grant of $545,630 to the Center for Open Science to work with Open Knowledge International (now called the Open Knowledge Foundation) and Ben Goldacre on creating a platform called OpenTrials. In theory, this was a great idea, as you can read in our press release at the time, or this article that Ben Goldacre published with Jonathan Gray of Open Knowledge in 2016.
In practice, it was hard to juggle and coordinate three independent groups within one grant. Folks had different ideas about the technological requirements and the path for future development. So ultimately, the grant stalled and never produced anything that was very functional.
In retrospect, I still think it’s a great idea for something that ought to exist, but it is technically difficult and would require lots of ongoing maintenance. I shouldn’t have tried to patch together three independent groups that each had their own ideas.
The 2014 Controversy Over Replication in Psychology
As of 2014, psychologists were starting to get nervous. The Reproducibility Project in Psychology was well under way, thanks to our funding, and would eventually be published in Science in 2015. A fair number of prominent psychological researchers knew far too well (or so I suspected) that their own work was quite flawed and likely to be irreplicable.
As a result, the 2014 time period was marked by a number of controversies over the role of replication in science, as well as the attitude and tone of debates on social media. I’ll spend a bit of time describing the controversies, not because they were all that strategically important, but just because I personally found it fascinating. Also, to this day, no one has fully catalogued all of the back-and-forth accusations, much of which I found only by looking for old expired links in emails or documents, and then going to the Internet Archive.
Brian Nosek and Daniel Lakens led a small replication project for a special issue of the journal Social Psychology in 2014 (with some small awards drawn out of the main COS grant). One of the replications was of a 2008 article by European researcher Simone Schnall, in which she and her colleagues had found that people who were primed to think about cleanliness or to cleanse themselves “found certain moral actions to be less wrong than did participants who had not been exposed to a cleanliness manipulation.”
The replication experiments – with much bigger sample sizes – found no such effect. One of the replication authors wrote a blog post titled, “Go Big or Go Home.” Brian Nosek, with his customary approach to openness, posted a long document with many emails back and forth amongst Schnall, the replication team, and the journal editors—all with permission, of course.
Simone Schnall then wrote a long blog post reacting to the replication and the accompanying commentary. She characterized her critics as bullies:

Here’s where it gets interesting.
On May 23, 2014, UCLA neuroscientist Matthew Lieberman posted this on Facebook:

Dan Gilbert of Harvard—the same Dan Gilbert whose TED talks have had over 33 million views, has appeared in several television commercials for Prudential Insurance, and whose articles have been cited over 55,000 times—posted this in response:

His comment about “second stringers” drew some attention elsewhere, and he then posted this:

That was followed by this:

On the blog post by Schnall, Gilbert’s comments were even more inflammatory, if that were possible:

In other words, someone whose work had been replicated was—merely on that account—the equivalent of Rosa Parks standing up against bigots and segregationists.
Gilbert also published an account on his own website, where he ended up concluding that calling replicators “shameless little bullies” was incorrect . . . because they might not be “little”:

And in an exchange on Twitter that was later deleted (Nick Brown found it on the Internet Archive, and I remember seeing it at the time), Gilbert said this:

I don’t bring all of this up to embarrass Gilbert—although I never saw that he retracted any insult other than the word “little,” or that he apologized for casting the replication debate in terms like “replication police,” “self-appointed sherrifs [sic],” “god’s chosen soldiers in a great jihad,” “Senator Joe McCarthy’s playbook,” “witch hunt,” “second stringers,” and “Rosa Parks.”
Instead, I bring it up to show the amount of vehement criticism in 2014 that was aimed at the Center for Open Science, Brian Nosek, and anyone trying to do replications. Since Gilbert was a prominent tenured professor at Harvard, he represented the height of the profession. We all assumed that there were other people who shared his views but were slightly less outspoken.
As for me, I not only took it in stride, but assumed that we at Arnold were doing good work. After all, replication is a core part of the scientific method. If folks like Gilbert were that upset, we must have struck a nerve, and one that deserved to be struck. To me, it was as if the IRS had announced that it would be auditing more tax returns of wealthy people, and then one wealthy person started preemptively complaining about a witch hunt while casting himself as Rosa Parks standing up against segregation—well, that person might well have something to hide. I remember joking to various folks at the time, “Should we fund a Dan Gilbert Replication Project?”
It did seem important that replications were:
Led by tenured professors at major universities, and
Funded by an outside philanthropy with no particular ax to grind and no stake in maintaining the good wishes of all psychologists everywhere.
The former made the replication efforts harder to dismiss as mere sour grapes or as the work of “second stringers” (Dan Gilbert’s efforts to the contrary). The latter made us at Arnold completely impervious to the complaints. I wonder if a program officer at NSF who was on a two-year leave from being a tenured professor of psychology might feel differently about antagonizing prominent members of the psychology community.
Reproducibility Project: Psychology
That leads us to the Reproducibility Project: Psychology, which at the time was the most ambitious replication project in history (it has since been handily surpassed by a DARPA program that my friend Adam Russell launched in partnership with COS). The aim was to replicate 100 psychology experiments published in top journals in 2008. In the Center for Open Science grant, we included an extra $250,000 for completing the Reproducibility Project, which had started but was unlikely to be finished given the current trajectory.
The final results were published in Science in 2015. Only around 40% (give or take) of the 100 experiments could definitively be replicated, while the rest were mixed or else definitely not replicable. These results took the academic world by storm. As of this writing, Google Scholar estimates that the 2015 Science paper has been cited over 7,500 times. It is a rare occasion when I mention this project and someone hasn’t heard of it. At $250k, it was easily the highest impact grant I ever made.
When the project was done, I got an inspiring email from Brian Nosek (it has been publicly posted on a Google Group, so this is all public knowledge). The email thanked us for supporting the project, and forwarded an email to his team thanking them for the heroic work they had done in pushing the project forward to completion. I remember finding it powerful and emotionally moving at the time, and that remains true today. It’s long, but worth quoting.
From: bno...@gmail.com [bno...@gmail.com] on behalf of Brian Nosek [no...@virginia.edu]
Sent: Wednesday, April 22, 2015 9:58 PM
To: Stuart Buck; Denis Calabrese
Subject: Reproducibility ProjectDear Stuart and Denis --
Today we completed and submitted the manuscript presenting the Reproducibility Project: Psychology. My note to the 270 co-authors on the project is below. When you funded the Reproducibility Project (and COS more broadly), the collaboration was active, exciting, and a patchwork.
LJAF funding gave us the excuse and opportunity to make it a "serious" effort. And, even though this project represents a very small part of our operating expenses, that support made an enormous difference.
If we had not received LJAF support, this project would have been a neat experiment with maybe a few dozen completed replications and contestable results. It would have received plenty of attention because of its unique approach, but I am doubtful that it would have had lasting impact.
With LJAF support, we had one person full-time on the project for our first year (Johanna), and two people for our second (+Mallory). We gave grants to replication teams and nominal payments to many others who helped in small and large ways. We helped all of the replication teams get their projects done, and then we audited their work, re-doing all of their analyses independently. We supported a small team to make sure that the project itself demonstrated all of the values and practices that comprise our mission. And, I could devote the time needed to make sure the project was done well. The project has been a centerpiece in the office for our two years of existence. Even though few in the office are working on it directly, they are all aware of the importance that it has for the mission of the organization. LJAF's support transformed this project from one that would have gotten lots of attention, to one that I believe will have a transformative impact.
I often tell my lab and the COS team about one of my favorite quotes for how we do our business. Bill Moyers asked Steve Martin, "What's the secret of success?" Steve responded, "Be so damn good that they can't ignore you."
LJAF funding gave us the opportunity to do this project in the best way that we could. Regardless of predictions, my thanks to both of you, Laura, and John for supporting this project and giving us the opportunity to do it well. I am so proud of it. I am confident that the scientific community will not be able to ignore it.
Best,
Brian
---------- Forwarded message ----------
From: Brian Nosek <no...@virginia.edu>
Date: Wed, Apr 22, 2015 at 10:50 PM
Subject: This is the end, or perhaps the beginning?
To: "Reproducibility Project: Psychology Team" <cos-reproducibility...@lists.cos.io>
Colleagues --I am attaching the submitted version of our Reproducibility Project: Psychology manuscript. [Figures need a bit of tweaking still for final version, but otherwise done.]
The seeds of this project were brewing with a few small-scale efforts in 2009 and 2010, and officially launched on November 4, 2011. Now, 3.5 years later, we have produced what must be the largest collective effort in the history of psychology. Moreover, the evidence is strong, and the findings are provocative.
For years, psychology conferences, journals, social media, and the general media has been filled with discussion of reproducibility. Is there a problem? How big is the problem? What should we do about it? Most of that discussion has been based on anecdote, small examples, logical analysis, simulation, or indirect inferences based on the available literature. Our project will ground this discussion in data. We cannot expect that our evidence will produce a sudden consensus, nor should it. But, we should expect that this paper will facilitate and mature the debate. That alone will be a substantial contribution.
To me, what is most remarkable about this project is that we did it. 270 authors and 86 volunteers contributed some or a lot of their time to the Reproducibility Project. If researchers were just self-interested actors, this could not have occurred. In the current reward system, no one is going to get a job or keep a job as an author on this paper.
. . .
The project will get a lot of attention. That won't necessarily be positive attention all the time, but it will get attention. I will receive much more than my share of attention and credit than I deserve based on our respective contributions. For that, I apologize in advance. In part, it is an unavoidable feature of large projects/teams. There is strong desire to talk about/through a single person.
But, there are also things that we can do to reduce it, and amplify the fact that this project exists because of the collective action of all, not the individual contribution of any. One part of that will be getting as many of us involved in the press/media coverage about the project as possible. Another part will be getting many of us involved in the presentations, posters, and discussions with our colleagues. We can emphasize the team, and correct colleagues when they say "Oh, Brian's project?" by responding "Well, Brian and 269 others, including me." [And, if they hate the project, do feel free to respond "Oh, yes, Brian's project."]
We all deserve credit for this work, and we can and should do what we can to ensure that everyone receives it. Does anyone know how to easily create a short video of the author list as a credit reel that we could all put into presentations?
Here, it would be difficult to call-out the contributions of everyone. I will mention just a few:
* Elizabeth Bartmess moved this fledgling project into a real thing when she started volunteering as a project coordinator in its early days. She was instrumental in turning the project from an interesting idea to a project that people realized could actually get done.
* Alexander Aarts made countless contributions at every step of the process - coding articles, editing manuscripts, reviewing submission requirements, and on on on. Much of getting the reporting details right is because of his superb contributions.
* Marcel van Assen, Chris Hartgerink, and Robbie van Aert led the meta-analysis of all the projects, pushing, twisting, and cajoling the diverse research applications into a single dataset. This was a huge effort over the last many weeks. That is reflected in the extensive analysis report in the supplementary information.
* Fred Hasselman led the creation of the beautiful figures for the main text of the report and provided much support to the analysis team.
* And, OBVIOUSLY, Johanna Cohoon and Mallory Kidwell are the pillars of this project. Last summer, more than 2 years in, it looked we wouldn't get much past 30 completed replications. Johanna and Mallory buckled down, wrote 100 on the wall, and pursued a steady press on the rest of us to get this done. They sent you (and me) thousands of emails, organized hundreds of tasks, wrote dozens of reports, organized countless materials, and just did whatever needed to be done to hit 100. They deserve hearty congratulations for pulling this off. Your email inbox will be lonely without them.
This short list massively under-represents all of the contributions to the project. So, I just say thank you. Thank you for your contributions. I get very emotional thinking about how so many of you did so much to get this done. I hope that you are as proud of the output as I am.
Warm regards,
Brian
That was a long email. But worth it—I still remember how emotional I felt when first reading it years ago. By the way, Johanna Cohoon and Mallory Kidwell deserve more recognition as key figures who made this project a reality. To them and many others, we should be grateful.

Reproducibility Project: Cancer Biology
Along with psychology, cancer biology seemed like a discipline that was early to the reproducibility crisis. In 2011-12, both Amgen and Bayer published articles bemoaning how rarely they were able to reproduce the academic literature, despite wanting desperately to do so (in order to find a drug to bring to market).
The Amgen findings were particularly dismal—they could replicate the literature only 11% of the time (6 out of 53 cases). I heard a similar message in private from top executives at Pfizer and Abbvie, with the gist being: “We always try to replicate an academic finding before carrying it forward, but we can’t get it to work 2/3rds of the time.”
Keep in mind that while pharma companies have a reputation (often justified) for trying to skew the results of clinical trials in their favor, they have no incentive to “disprove” or “fail to replicate” early-stage lab studies. Quite the contrary—they have every incentive to figure out a way to make it work if at all possible, so that they can carry forward a research program with a solid drug candidate. The fact that pharma companies still have such trouble replicating academic work is a real problem.
Around that time, Elizabeth Iorns launched the Reproducibility Initiative to address the problems of cancer biology. I ended up funding her in partnership with the Center for Open Science (where Tim Errington led the effort) to try to replicate 50 cancer biology papers from top journals (some coverage from Science at the time).
The project was quite a journey. It took longer than expected, cost more (they had to ask for supplemental funding at one point), and completed far fewer replications (only 23 papers, not 50). This might look like the project was inefficient in every possible way, but that wasn’t the case at all. The reason was that the underlying literature was so inadequate that the project leaders were never able to start a replication experiment without reaching out the original authors and labs. Never. Not even one case where they could just start up the replication experiment.
The original authors and labs weren’t always cooperative either—only 41% of the time. Indeed, the replicators were unable to figure out the basic descriptive and inferential statistics for 68% of the original experiments, even with the authors’ help (where provided)!
The end results? For studies where one could calculate an effect size (such as, how many days does a cancerous mouse survive with a particular drug?), the replication effect was on average 85% smaller than the original (e.g., the mouse survived 3 days rather than 20 days). And for studies where the effect was binary (yes-no), the replication rate was 46%. In any case, it looked like the original effects were overestimated compared to the replications.
As for what this implies for the field of cancer biology, see coverage in Wired, Nature, and Science. [Note: the coverage would have been far greater if not for the fact that the Washington Post, New York Times, and NPR all canceled stories at the last minute due to the Omicron wave.] Science had a useful graphic of which studies replicated and how often they have been cited in the field:

Science also quoted my friend Mike Lauer from NIH, whose thoughts mirror my own:
The findings are “incredibly important,” Michael Lauer, deputy director for extramural research at the National Institutes of Health (NIH), told reporters last week, before the summary papers appeared. At the same time, Lauer noted the lower effect sizes are not surprising because they are “consistent with … publication bias”—that is, the fact that the most dramatic and positive effects are the most likely to be published. And the findings don’t mean “all science is untrustworthy,” Lauer said.
True, not all science is untrustworthy. But at a minimum, we need to figure out how to prevent publication bias and a failure to report complete methods.
RIAT (Restoring Invisible and Abandoned Trials)
I first came across Peter Doshi due to his involvement in reanalyzing all of the clinical trial data as to Tamiflu, leading to the conclusion that governments around the world had stockpiled Tamiflu based on overestimates of its efficacy. Similarly, an effort to reanalyze the famous Study 329 on the efficacy of paroxetine (Paxil) to treat depression in adolescents showed that not only did the drug not work, there was an “increase in harms.” (GSK’s earlier attempt to market Paxil to adolescents–despite the fact that the FDA denied such approval--had been a key factor in a staggering $3 billion settlement with the federal government in 2012.) These and other examples suggested that misreported (or unreported) clinical trials could lead to significant public expense and even public harms.
Doshi and co-authors (including the famous Kay Dickersin) wrote a piece in 2013 calling for “restoring invisible and abandoned trials.” They gave numerous examples of trial information (drawn from documents made public via litigation or in Europe) that had been withheld from the public:
The documents we have obtained include trial reports for studies that remain unpublished years after completion (such as Roche’s study M76001, the largest treatment trial of oseltamivir, and Pfizer’s study A945-1008, the largest trial of gabapentin for painful diabetic neuropathy). We also have thousands of pages of clinical study reports associated with trials that have been published in scientific journals but shown to contain inaccuracies, such as Roche’s oseltamivir study WV15671, GlaxoSmithKline’s paroxetine study 329, and Pfizer’s gabapentin study 945-291. We consider these to be examples of abandoned trials: either unpublished trials for which sponsors are no longer actively working to publish or published trials that are documented as misreported but for which authors do not correct the record using established means such as a correction or retraction (which is an abandonment of responsibility) (box 1).Because abandonment can lead to false conclusions about effectiveness and safety, we believe that it should be tackled through independent publication and republication of trials.
In 2017, I was able to award a grant to Peter Doshi of $1.44 million to set up the RIAT Support Center—with RIAT standing for Restoring Invisible and Abandoned Trials. Doshi’s Center, in turn, made several smaller grants to outside researchers to reanalyze important clinical trials in areas ranging from cardiovascular disease to depression to nerve pain (gabapentin specifically).
I continue to think that this kind of work is vastly undersupplied. Few people have the resources, patience, or the academic incentive to spend years poring through potentially thousands of documents (including patient records) just to reanalyze one clinical trial to see whether the benefits and adverse events were accurately recorded. NIH should set aside, say, $5 million a year for this purpose, which be a pittance compared to what it spends on clinical trials each year (up to a thousand times more than that!).
REPEAT Initiative
I can’t remember how I first came across Sebastian Schneeweiss and his colleague Shirley Wang, both of whom holding leading roles at Harvard Medical School and at the Division of Pharmacoepidemiology and Pharmacoeconomics at Brigham and Women's Hospital.
I do remember inviting them down to Houston to meet with the Arnolds in order to pitch their idea: they wanted to review studies using “big data” in medicine (e.g., epidemiology, drug surveillance, etc.) in order to 1) assess the transparency of 250 of them, and 2) try to replicate 150 studies. Note: The replications here don’t mean rerunning experiments, but rerunning code on the same databases as in the original study.
This sort of systematic study seemed important, given that in the 21st Century Cures Act, the federal government had promoted the idea that drugs could be approved based on “real world evidence,” meaning “data regarding the usage, or the potential benefits or risks, of a drug derived from sources other than randomized clinical trials” (see section 3022 here).
How reliable is that “real world evidence” anyway? No one knew.
We ended up giving a $2 million grant to launch the REPEAT Initiative at Harvard, with REPEAT standing for “Reproducible Evidence: Practices to Enhance and Achieve Transparency.” A 2022 publication from this project noted that it was the “largest and most systematic evaluation of reproducibility and reporting-transparency for [real-world evidence] studies ever conducted.”
The overall finding was that the replication “effect sizes were strongly correlated between the original publications and study reproductions in the same data sources,” but that that there was room for improvement (since some findings couldn’t be reproduced even with the same methods and data).
This overall finding is an understatement, of course. If a drug is approved to market to the US population, what we really care about is whether the original finding still applies to new data/people/etc. If we could do a broader replication project, I’m fairly certain that we would find more discrepancies between what the FDA approved and what actually works in the real world.
The researchers at the REPEAT Initiative (Wang and Schneeweiss) since procured an award from FDA to use health claims databases to try to replicate key RCTs. Their initial results show that a “highly selected, nonrepresentative sample” of “real-world evidence studies can reach similar conclusions as RCTs when design and measurements can be closely emulated, but this may be difficult to achieve.” They also note that “emulation differences, chance, and residual confounding can contribute to divergence in results and are difficult to disentangle.”
In other words, the political enthusiasm for “real-world evidence” as a substitute for rigorous RCTs (rather than a complement) is overly naïve—at least as it would be implemented, well, in the real world.
Publication Standards at the journal Nature
Around 2014, Malcolm McLeod, a professor of Neurology and Translational Neuroscience at the University of Edinburgh (and one of the most hilariously droll people I’ve ever met) wanted to evaluate Nature’s new editorial requirements for research in the life sciences.
I gave him a grant of $82,859 to do so. He and his colleagues compared 394 articles in the Nature set of journals to 353 similar articles in other journals, including articles both before and after the change in Nature’s standards. The team looked at the number of articles that satisfied four criteria (information on randomization, blinding, sample size, and exclusions).
The findings were that in Nature-related articles, the number of articles that met all four criteria went from 0% to 16.4% after the change in guidelines, but the number of such articles in other journals stayed near zero over the whole timeframe.
In other words, a change in journal guidelines increased the number of articles that met basic quality standards, but there was still a long way to go. Thus, their findings encapsulated the entire open science movement: Some progress, but lots more to come.
Computer Science
In 2015, I made a grant of $357,468 to Todd Proebsting and Christian Collberg at the University of Arizona to do a longitudinal study of how computer scientists share data and research artifacts. They published a study in 2016 (also here) on “repeatability in computer systems research,” with the findings represented in this colored/numbered flow chart:

They also produced this website cataloguing 20,660 articles from 78,945 authors (at present) and the availability of code and data. To repeat myself, this seems like the sort of thing that NSF ought to support in perpetuity.
Transcranial Direct Current Stimulation
In 2015, I gave the Center for Open Science a grant of $41,212 to work with another researcher to try to replicate one or more experiments using transcranial direct current stimulation, a popular but controversial treatment where replication seemed like it would turn up useful insights (as shown by subsequent studies). This grant was a failure: The outside researcher never completed the project. Not much more to say about this one.
II. Make It Possible and Make It Easy: software, databases, and other tools to help improve reproducibility
One of the most important ways to improve science (so I thought) was to provide better tools, software, etc., so that scientists would have more readily available ways to do good work. After all, one of the most common excuses for failing to share data/methods/code was that it was just too hard and time-consuming. If we could help remove that excuse, perhaps more scientists would engage in good practices.
Open Science Framework
A significant part of the funding for the Center for Open Science was always the development of the Open Science Framework software/website. To this day, COS’s staff includes 15+ people who work on software and product development.
What was OSF? From the beginning, I saw it as a software platform that allowed scientists to create a wiki-style page for each research project, share with collaborators, track changes over time, and more. Along the way, the platform also enabled preregistration (by freezing in time the current status of a given project) and preprints (by allowing access to PDFs or other versions of articles). Indeed, its SocArXiv preprint service currently hosts over 13,000 papers as a free and open source alternative to SSRN (the Social Science Research Network), and OSF is home to around 140,000 preregistrations.
As other examples, OSF was recently listed as one of the few data repositories that the NIH recommends for complying with its new data-sharing policy. Among many other institutional partners, the Harvard Library recommends OSF to the Harvard community, and offers ways to link OSF to a Harvard account (see here).
I’ll quote from a Twitter thread by Brian Nosek from last August on the occasion of OSF having 500,000 registered users:
How much has open science accelerated?
OSF launched in 2012. In its first year, we had less than 400 users. In 2022, OSF averages 469 new registered users per day, every day.
OSF consumers don't need an account. More than 13M people have consumed OSF content so far in 2022.
Other daily averages for 2022 so far:
202 new projects every day
9105 files posted every day
5964 files made publicly accessible every day
93 studies registered every day
Vivli
Clinical trials in medicine always seemed to me like the quintessential case where we ought to have the full evidence before us. Sure, if some trendy social psychology studies on power posing and the like were p-hacked, that would be troubling and we might end up buying the wrong book in an airport bookstore or being too credulous at a TED talk. But when medical trials were faked or p-hacked, cancer patients might end up spending thousands on a drug that didn’t actually work or that even made things worse. The stakes seemed higher.
In the 2013-14 timeframe, I noticed that there were many efforts to share clinical trial data—too many, in fact. The Yale Open Data Alliance was sharing data from Medtronic and J&J trials; Duke was sharing data from Bristol; Pfizer had its own Blue Button initiative; GSK had set up its own site to share data from GSK and other companies; and there were more.
Sharing data is most useful if done on a universal basis where everyone can search, access, and reanalyze data no matter what the source. That wasn’t occurring here. Companies and academia were all sharing clinical trial data in inconsistent ways across inconsistent websites. If someone wanted to reanalyze or do a meta-analysis on a category of drugs (say, antidepressant drugs from multiple companies), there was no way to do that.
Thus, I had the thought: What if there were a one-stop-shop for clinical trial data? A site that hosted data but also linked to and pulled in data from all the other sites, so that researchers interested in replication or meta-analysis could draw on data from everywhere? They would be far better able to do their work.
I asked around: Was anyone doing this? If not, why not? The answer was always: “No, but someone should do this!”
I ended up giving a small grant to Barbara Bierer at Harvard (and Brigham and Women’s Hospital in Boston) at the Multi-Regional Clinical Trials Center at Brigham and Women's Hospital and Harvard to have a conference on clinical trial data-sharing. The conference was well-attended, and I remember seeing folks like Deb Zarin, then the director of Clinicals.gov, and Mike Lauer, who was then at NHLBI and now is the Director of Extramural Research at NIH.
After that, I gave a planning grant of $500,000 to Bierer and her colleagues to help create a clinical trial data-sharing platform, plus a $2 million grant in 2017 to actually launch the platform. The result was Vivli. After a $200k supplemental grant in 2019, Vivli was on its own as a self-sufficient platform. As of 2023, Vivli shares data from 6,600+ clinical trials with over 3.6 million participants.
By those metrics, Vivli is by far the biggest repository for clinical trial data in the world. But not enough people request Vivli data. The last I heard, the number of data requests was far less than one per trial.
This leads to a disturbing thought about platforms and policies on data-sharing (for example, the NIH’s new data-sharing rule that went into effect in January 2023). That is, why should we spend so much effort, money, and time on sharing data if hardly anyone else wants to request and reuse someone else’s data in the first place? It’s an existential question for folks who care about research quality—what if we built it and no one came?
That said, we could improve both PhD education and the reuse of data in one fell swoop: If you’re doing a PhD in anything like biostatistics, epidemiology, etc., you should have to pick a trial or publication, download the data from a place like Vivli or various NIH repositories, and try to replicate the analysis (preferably exploring additional ideas as well).
Who knows what would happen—perhaps a number of studies would stand up, but others wouldn’t (as seen in a similar psychology project). In any event, the number of replications would be considerable, and it would be valuable training for the doctoral students. Two birds, one stone.
Declare Design
One key problem for high-quality research is that while there are many innovations as to experimental design, fixed effects, difference-in-differences, etc., there often isn’t a good way to do analyze these designs ahead of time. What will be your statistical power? The possible effects of sampling bias? The expected root mean squared error? The robustness across multiple tests? For these and many other questions, there might not be any simple numerical solution.
Enter DeclareDesign. The idea behind DeclareDesign is that you “declare” in advance the “design” of your study, and then the program does simulations that help you get a handle on how that study design will work out.
The folks behind DeclareDesign were all political scientists, whom I met through an introduction from Don Green around 2015 or so:
Graeme Blair, Associate Professor of Political Science at UCLA.
Jasper Cooper, then in the middle of a PhD in political science at Columbia, and now a Portfolio Lead at the Office of Evaluation Sciences at the General Services Administration.
Alexander Coppock, Associate Professor of Political Science at Yale.
Macartan Humphreys, at the time a Professor of Political Science at Columbia, and currently director of the Institutions and Political Inequality group at the WZB Berlin Social Science Center and honorary professor of social sciences at Humboldt University.
In 2016, they put out the first draft of an article on their idea. It was eventually published in the American Political Science Review in 2019. As they write:
Formally declaring research designs as objects in the manner we describe here brings, we hope, four benefits. It can facilitate the diagnosis of designs in terms of their ability to answer the questions we want answered under specified conditions; it can assist in the improvement of research designs through comparison with alternatives; it can enhance research transparency by making design choices explicit; and it can provide strategies to assist principled replication and reanalysis of published research.
I gave them a grant of $447,572 in 2016 to help build out their software, which is primarily written in R, but the grant was also intended to help them build a web interface that didn’t require any coding ability (DDWizard, released in 2020).
The software got a positive reception from social scientists across different disciplines. A flavor of the reactions:
A major university professor once wrote to me DeclareDesign was an "incredible contribution to academic social science research and to policy evaluation."
A Dartmouth professor posted on Twitter that “it’s an amazing resource by super smart people for research design and thinking through our theories and assumptions.”
A political scientist at Washington University-St. Louis wrote: “It is remarkable how many methods questions I answer these days just by recommending DeclareDesign. Such an awesome piece of software.”
An Oxford professor of neuropsychology wrote: “It's complex and difficult at first, but it does a fantastic job of using simulations not just to estimate power, but also to evaluate a research design in terms of other things, like bias or cost.”
I do think that this was a good investment; beyond Twitter anecdotes, DeclareDesign won the 2019 “Best Statistical Software Award” from the Society for Political Methodology. Blair, Coppock and Humphreys are about to publish a book on the whole approach: Research Design in the Social Sciences. I hope that DeclareDesign continues to help scholars design the best studies possible.
Center for Reproducible Neuroscience
Here is a grant that can be traced to the power of Twitter. In Oct. 2014, I noticed a tweet by Russ Poldrack at Stanford. Poldrack and I had the following interaction:


Russ and I talked, along with his colleague Krzysztof (Chris) Gorgolewski. Long story short, I was able to give them a grant of $3.6 million in 2015 to launch the Stanford Center for Reproducible Neuroscience. The intent was to promote data sharing in neuroscience, as well as higher data quality standards for a field that had been plagued by criticisms for quite some time (see the infamous 2009 paper involving a brain scan of dead fish). The critiques continue to this day (see a recent Nature study showing that most brain-wide association studies are vastly underpowered).
The project has been quite successful in the years since. First, the OpenNeuro archive that was the main focus of the project was launched in 2017. It has grown consistently since then, and now hosts brain imaging data from more than 33,000 individuals and 872 different datasets. It is one of the official data archives of the BRAIN Initiative, and just received its second five-year round of NIH funding (which will go from 2023-2028).
Second, the Brain Imaging Data Structure (or BIDS) standard that was developed to support data organization for OpenNeuro has been remarkably successful. When Chris Gorgolewski left academia in 2019, it became a community project with an elected Steering Group and well over 100 contributors to date. One of the ideas that Chris developed was the "BIDS App" which is a containerized application that processes a BIDS dataset. One of these, fMRIPrep, has been widely used—according to Poldrack, there had been over 4,000 successful runs of the software per week over the last 6 months.
Indeed, a draft article on the history of the BIDS standard—which is now expected practice in neuroscience—includes this sentence: “The birth of BIDS can be traced back ultimately to a Twitter post by Russ Poldrack on October 17, 2014.” The paragraph then discusses the interaction between me and Russ (shown above).
This story shows not just the power of Twitter, but the power of publicly sharing information and ideas about what you’re working on—you never know who will read it, and start a conversation that leads to something like a whole new set of data standards for neuroscience.
Stealth Software Technologies
My friend Danny Goroff (usually at the Sloan Foundation, but currently at the White House) introduced me to the topic of privacy-preserving computation, such as secure multi-party computation or fully homomorphic encryption. It would take too long to explain here, but there are ways that you could write a regression equation and compute it on data that remains entirely private to you the entire time, and there are ways to match and merge data from sources that keep their data private the whole time.
The possibilities seemed endless. One of the biggest obstacles to evidence-based policy is how hard it is to access private data on sensitive issues (health, criminal justice, etc.), let alone match and merge that data with other sources (e.g., income or schooling) so that you can research how housing/schooling affects health or criminal outcomes.
It seemed like every researcher working in these areas had to spend way too much time and money on negotiating relationships with individual state/federal agencies and then figuring out the legalities of data access. If there was a way to do all of this computation while keeping the underlying data private the entire time, it might be a shortcut around many of the legal obstacles to working with highly private data.
I spent a year (in my spare time) reading books on computation and encryption before I finally felt comfortable pitching a grant to the Arnolds on this topic. I also talked to Craig Gentry, who invented fully homomorphic encryption in his graduate dissertation (and then went to work for IBM).
I ended up making a grant of $1,840,267 to Stealth Software Technologies, a company formed by Rafail Ostrovsky of UCLA (one of the giants in the field) and Wes Skeith. Ostrovsky had primarily been funded by DARPA. The grant included working with ICPSR, the Inter-university Consortium for Political and Social Research, one of the largest data repositories in the world for social science data. Our goal was to find ways to do social science research that combined data from two different sources (e.g., an education agency and a health agency) while keeping data provably private the entire time.
The result was an open-source set of software (available here), although it still needs more explanation, marketing, and use. The team has given talks at NIST on secure computation, and has worked with Senator Ron Wyden on proposing the Secure Research Data Network Act, which would authorize a multi-million pilot at NSF using secure multi-computation to help create much more “research that could support smart, evidence-based policymaking.”
The same group (Stealth Software Technologies and George Alter) have also engaged in a DARPA-funded collaboration with the state of Virginia to produce a working version of the cryptographic software that will be used on a regular basis. The goal in the Virginia government is to get more agency participation in sharing private data and/or improving the capabilities of the Virginia Longitudinal Data System.
III. Make It Normative
Journalists/Websites
As much as everyone says that “science is self-correcting,” an ironic downside of the academic incentive system is that there are essentially no rewards for actively calling out problems in a given field (as my friend Simine Vazire and her spouse Alex Holcombe have written). There are no tenure-track positions in “noticing replicability issues with other people’s research,” no academic departments devoted to replication or the discovery of academic fraud, and very few government grants (if any). On top of that, as we’ve seen above, people who devote hundreds or thousands of hours to replication or uncovering fraud often find themselves with no academic job while being threatened with lawsuits.
It is a thankless task. “Science is self-correcting”—sure, if you don’t mind being an outcast.
Yet public correction is necessary. Otherwise, individual scientists or even entire academic fields can coast for years or decades without being held to account. Public scrutiny can create pressure to improve research standards, as has been seen in fields such as medicine and psychology. That’s why one line of Arnold funding was devoted to supporting websites and journalists that called out research problems.
Retraction Watch
One oddity in scholarly communication is that even when articles are retracted, other scholars keep citing them. Historically, there just wasn’t a good way to let everyone know, “Stop citing this piece, except as an example of retracted work.” But now that we have the Internet, that isn’t really an excuse.
As it turns out, journal websites often don’t highlight the fact that an article was retracted. Thus, one article that reviewed papers from 1960-2020 found that “retraction did not change the way the retracted papers were cited,” and only 5.4% of the citations even bothered to acknowledge the retraction. There are many more articles on this unfortunate phenomenon (see here and here).
Retraction Watch is one of the most successful journalistic outlets focused on problematic research since its launch in 2010 by Ivan Oransky and Adam Marcus. Marcus, the editorial director for primary care at Medscape, is the former managing editor of Gastroenterology & Endoscopy News, and has done a lot of freelance science journalism. Oransky, the editor in chief of Spectrum, a publication about autism research, is also a Distinguished Writer In Residence at New York University’s Carter Journalism Institute, and has previously held leadership positions at Medscape, Reuters Health, Scientific American, and The Scientist. It has published thousands of blog posts (or articles) on problematic research.
In 2014, John Arnold emailed me about this Retraction Watch post asking for donations. I looked into it, and eventually Retraction Watch pitched me on a database of retractions in the scholarly literature in order to help scholars keep track of what not to cite. In 2015, we awarded Retraction Watch a grant of $280,926 to partner with the Center for Open Science on that effort. The database is available here, and as a recent post stated:
Our list of retracted or withdrawn COVID-19 papers is up to more than 300. There are now 41,000 retractions in our database — which powers retraction alerts in EndNote, LibKey, Papers, and Zotero. The Retraction Watch Hijacked Journal Checker now contains 200 titles. And have you seen our leaderboard of authors with the most retractions lately — or our list of top 10 most highly cited retracted papers?
In other words, the Retraction Watch database has been created and populated with 41,000+ entries, and has partnered with several citation services to help scholars avoid citing retracted articles. Indeed, a recent paper found the following: "reporting retractions on RW significantly reduced post-retraction citations of non-swiftly retracted articles in biomedical sciences."
Even by 2018, there were many interesting findings from this database, as documented in a Science article. The Science article also quotes a notable metascience scholar (Hilda Bastian):
Such discussions underscore how far the dialogue around retractions has advanced since those disturbing headlines from nearly a decade ago. And although the Retraction Watch database has brought new data to the discussions, it also serves as a reminder of how much researchers still don't understand about the prevalence, causes, and impacts of retractions. Data gaps mean "you have to take the entire literature [on retractions] with a grain of salt," Bastian says. "Nobody knows what all the retracted articles are. The publishers don't make that easy."
Bastian is incredulous that Oransky's and Marcus's "passion project" is, so far, the most comprehensive source of information about a key issue in scientific publishing. A database of retractions "is a really serious and necessary piece of infrastructure," she says. But the lack of long-term funding for such efforts means that infrastructure is "fragile, and it shouldn't be."
I obviously agree. One of my perpetual frustrations was that even though NIH and NSF were spending many times Arnold’s entire endowment every single year, comparatively little is spent on infrastructure or metascience efforts that would be an enormous public good. Instead, we at Arnold were constantly in the position of awarding $300k to a project that, in any rational system, would be a no-brainer for NIH or NSF to support at $1 or $2 million a year forever.
PubPeer
PubPeer is a discussion board that was launched in 2012 as a way for anonymous whistleblowers to point out flaws or fraud in scientific research. It has since become a focal point for such discussions. While anonymous discussion boards can be fraught with difficulties themselves (i.e., people who just want to harass someone else, or throw out baseless accusations), PubPeer seemed to take a responsible approach—it requires that comments be based on “publicly verifiable information” and that they not include “allegations of misconduct.” Are there occasions where an anonymous commenter might have valuable inside information about misconduct? For sure. But valid comments could be lost in a swarm of trolls, saboteurs, etc. PubPeer decided to focus only on verifiable problems with scientific data.
I initially gave PubPeer a grant of $412,800 in 2016 as general operating support; this was followed by a $150,000 general operating grant in 2019. The 2016 grant enabled PubPeer to “hire a very talented new programmer to work on the site full-time and completely rewrite it to make it easier to add some of the ideas we have for new features in the future.” In particular, a previous lawsuit had tried to order PubPeer to provide information about commenters who had allegedly cost a professor a job due to research irregularities (or possible fraud). PubPeer used our funding to revamp so as to be completely unable “to reveal any user information if we receive another subpoena or if the site is hacked.” As well, thanks to Laura Arnold’s membership on the ACLU’s national board, I was able to introduce PubPeer to folks at the ACLU who helped defend the lawsuit.
While it can often be difficult to know the counterfactual in philanthropy (“would the same good work have happened anyway?”), I’m fairly confident in this case that without our grant and the introduction to the ACLU, PubPeer would likely have been forced to shut down.
I thought, and still think, that this sort of outlet is enormously useful. Just last year, a major scandal in Alzheimer’s research was first exposed by commenters on PubPeer—not by grant peer review, journal peer review, or by the NIH grant reports that had been submitted over a decade before. And as I say throughout, it seems like a no-brainer for NIH or NSF to support this sort of effort with $1-2 million a year indefinitely. We have very few ways of collecting whistleblower information about fraud or other research problems that many people (particularly younger scientists) might be reluctant to bring up otherwise.
HealthNewsReview
HealthNewsReview (now defunct) was a website run by Gary Schwitzer, a former medical correspondent for CNN and journalism professor at the University of Minnesota. The focus was providing regular, structured critiques of health/science journalism. In 2008, Ben Goldacre had written about a HealthNewsReview study showing that out of 500 health articles in the United States, only 35% had competently “discussed the study methodology and the quality of the evidence.” The site had come up with 10 criteria for responsible journalism about health/science studies, such as whether the story discusses costs, quantifies benefits in meaningful terms, explains possible harms, compares to existing alternatives, looks for independence and conflicts of interest, reviews the study’s methodology and evidentiary quality, and more.
The site seemed to be widely respected among health journalists, but had run out of funding. I thought their efforts were important and worth reviving. As a result, in 2014, I gave a $1.24 million grant to the University of Minnesota for Gary Schwitzer’s efforts at HealthNewsReview, and this was followed by a $1.6 million grant in 2016.
One of their most widely-known successes was the case of the “chocolate milk, concussion” story. In late 2015, the University of Maryland put out a press release claiming that chocolate milk “helped high school football players improve their cognitive and motor function over the course of a season, even after experiencing concussions.” A journalist who worked for HealthNewsReview started asking questions, such as “where is the study in question?”
Boy, was he in for a surprise when the Univ. of Maryland called him back:
The next morning I received a call from the MIPS news office contact listed on the news release, Eric Schurr. What I heard astounded me. I couldn’t find any journal article because there wasn’t one. Not only wasn’t this study published, it might never be submitted for publication. There wasn’t even an unpublished report they could send me.
The story became a major scandal for the University of Maryland. The university did its own internal review, which Schwitzer then characterized as a “scathing self-reflection, in which they admitted the research was schlocky, conflicts of interests that should have been reported, and no clear lines of authority for who approved news releases.”
As one journalist wrote in 2014 after my grant: “HealthNewsReview won numerous awards, and, more importantly, kept many medical reporters on their toes–including me. . . . It’s great to see Schwitzer back. Although there is a downside–I, and many of my colleagues, will once again be looking nervously over our shoulders. But that’s not so bad–our reporting will surely be the better for it.”
By the end of their run, they had analyzed 2,616 news stories and 606 PR news releases. They had also published 2,946 blog posts, 50 podcasts, and a fairly extensive toolkit of resources for journalists and the general public. But HealthNewsReview is no more. Even the website registration has expired. I still wish that a funder like NIH would support efforts like HealthNewsReview to improve how science is communicated to the public.
Standards/Ratings as to Research Quality and Transparency
One of the most replicable features of human beings is our incessant need to compete with each other, even as to measures that we know are irrational. There is a large psychology literature on how people can be drawn into mindless competition with others, even if it’s only a room divided randomly into Group A and Group B, or people with blue eyes versus people with brown eyes. More relevant here, universities compete tooth and nail to rise in the US News rankings, even though they all know that the rankings depend on fairly arbitrary factors.
Can we harness that universal human drive for a good purpose? Can we find ways to measure and rank scientific publications on a variety of metrics that relate to good science, and then watch people try to maximize those metrics rather than just maximizing citations?
Maybe so. I still have mixed feelings about this line of work (Goodhart’s law, and all that), and I wish we could set up some carefully targeted experiments that would show the effects (good or ill) of such interventions.
As it was, I funded the following efforts:
TOP Guidelines
The TOP (Transparency and Openness Promotion) Guidelines started out as an idea that Marcia McNutt and I kicked around the first time we met in person (we had emailed previously). It was during a break at an NSF workshop on scientific reproducibility in February 2014. Marcia was then the editor of Science (she has since become the first female president of the National Academies); she said that maybe we could fund some workshops on the standards for scientific publication, and I enthusiastically agreed.
Brian Nosek happened to walk up to say hello, and joined in what was now a 3-person conversation. We all started brainstorming on how we could bring together prominent scholars and journal editors from multiple fields in order to get some consensus on improved standards.
After that conversation, I quickly got the Arnolds to approve a $100k grant to AAAS (the American Association for the Advancement of Science, which publishes Science). A side comment on philanthropy: That was one of the highest impact grants I ever made, and with the least effort to boot—I sent a brief email, and the grant was approved in under 45 minutes. Hardly anyone in philanthropy works with that level of dexterity, and the philanthropic sector should put more thought into this issue.
Anyway, with the $100k in hand, AAAS worked with the Center for Open Science to host workshops on developing new and better standards for scientific publication, such as preregistration, sharing methods, sharing data, sharing code, and more. As to each standard of behavior, there would be multiple levels as to which a journal or funder could land—not mentioning it at all, mentioning it, favoring it, or mandating it.
We held the first workshop in 2014 at the Center for Open Science’s headquarters in Charlottesville, Virginia. Along with the other organizers, I put in much work figuring out who to invite.
We ended up with folks from many disciplines, which had its pros and cons. I particularly remember that someone commented afterwards that they had never seen someone interrupt to object to the title slide of a presentation (it was my friend Josh Angrist of MIT, also a substantial grantee, and someone who later won the Nobel in Economics—Josh is brilliant but takes no prisoners, and well, economists act differently in seminars than psychological researchers).
The first workshop was a success by all measures, and we all worked over the next few months to co-publish a statement in Science: Promoting an Open Research Culture. The resulting TOP Guidelines are a set of eight standards that each have three different levels of rigor. For example, one standard is about preregistration—level one of the TOP Guidelines involves merely stating whether preregistration happened at all, level two allows the journal access to the preregistration during peer review, and level three is that preregistration is required before publication. The same sort of differential levels can be seen for the other TOP standards, such as replication and data sharing.
By now, more than 5,000 journals, publishers, foundations, and other organizations have at least endorsed the TOP Guidelines. Science itself later adopted the guidelines at varying levels for its own publication practices. The TOP Guidelines are easily the most widely-adopted publication guidelines in the world.
That said, a lot of work remains to be done. A follow-up initiative that I supported (TOP Factor) evaluates journal policies to see whether they actually comport with the TOP Guidelines. Many don’t comply that well, even if they endorsed the Guidelines at an earlier point.
Which goes to show one of the chief challenges for reproducibility: It is far too easy to gain points by “endorsing” an idea or a particular set of standards, even if one doesn’t actually comply with or enforce those standards when push comes to shove. We need better ways of tracking compliance and behavior so that we’re not fooled by anyone who is engaging in “performative reproducibility” (to use a term from a piece that Nature solicited from me in 2021).
Good Pharma Scorecard
A recurring question as to pharmaceutical companies is whether they correctly and timely report data on the effects and side effects of drugs and other treatments. If not, was there a way to hold them accountable in the public eye?
I’ll never forget the first time I met Jennifer (Jen) Miller in 2013, who was then an assistant professor at the New York University School of Medicine. She reached out to me by email, and I agreed to meet for lunch. We went to a restaurant that was walking distance to the Arnold Foundation’s offices. I ended up spending 2 hours there as she walked me through various slides and data on her laptop, all about how pharma companies reported on the results of their clinical trials. She argued that a rating system would incentivize these companies to be better behaved.
I thought there was something to this, but I wanted confirmation. So I called up Rob Califf (who was then at Duke, and who has since been the FDA Commissioner twice over). Califf had worked with Miller, and I wanted his opinion. He told me that Jen Miller was definitely worth funding.
In 2015, I ended up making a $4 million grant to Miller’s Good Pharma Scorecard. The basic idea was to measure and rate pharmaceutical companies on their practices as to transparency, data sharing, clinical trial design, accessibility, and more. With a public ranking, they would be incentivized to improve their practices.
You might think that this idea is naïve, and that pharma companies only care about the bottom line. Maybe so, but I went to one of the Good Pharma Scorecard meetings in New York, and many top pharma executives were in attendance—it was obvious from their comments (and just from their presence) that they deeply cared about how their company was rated as to transparency and quality of research. To be sure, they cared about whether they would be downgraded on some metric, and how that metric was applied or defined. If they could have gamed that metric, they probably would have. But the point is that they cared. Even if it had been just Miller and her team of investigators from Yale School of Medicine and Stanford Law School who say so, companies cared about their public ranking. It was fascinating to observe this dynamic in action.
Since the original grant, Jen Miller moved from NYU to the Yale School of Medicine, where she is an associate professor. As a result of her efforts, transparency and data sharing practices have measurably improved year after year, with 50% of large companies improving their data sharing practices within 30 days of getting a low score from Bioethics International.
Based on this evidence of impact, she expanded the Good Pharma Scorecard’s scope to include a ranking on companies’ fair inclusion of women, older adults and racial and ethnic minorities in clinical research. The problem here is that we often test new medicines and vaccines in patients who are healthier, younger and more likely to identify as white and male than real world patients.
The FDA Oncology Center for Excellence awarded her a grant to expand her work. She is conducting a positive deviance study, which involves identifying pharmaceutical companies demonstrating exceptionally high performance on specific Good Pharma Scorecard measures, in this case adequate representation of older adults, women, Asian, Black or Latino patients in trials supporting new cancer therapeutics, and then conducting qualitative research to understand how these leaders achieved their top performance. This allows for the identification of practices, strategies, and factors shared by positive deviants (aka leaders), allowing them to achieve top performance.
The Scorecard continues to grow in impact and visibility. Companies cite their scores and badges in their annual reports, CEO letters, and human rights due diligence, when they score well. Miller partnered with Deloitte last year to host the annual conference on the Scorecard’s accountability metrics, and will host this year’s meeting with E&Y on 9/15, which is even better attended now than the event I first attended many years ago. Further, the annual meeting includes a growing number of socially responsible and impact investors, who can be further levers for change and incentivize adoption of the scorecard measures. Scientific American is the Scorecard’s media partner, helping elevate its visibility to their audience of over 8million.
Rating Social Programs Funded by the Federal Government
The U.S. government spends many billions of dollars every year on social programs or interventions that are intended to prevent teen pregnancy, prevent drug abuse, improve education, reduce crime, and much more. Many of these programs don’t actually work very well, if at all. Yet there were many websites purporting to list and rate programs on their efficacy—the What Works Clearinghouse, CrimeSolutions.gov, and many more.
In the past, these evidence clearinghouses usually included barebones measures of research quality (such as “is it an RCT?”) but not more nuanced measures (such as, “was the RCT preregistered?”). I made a grant of $238,975 to Sean Grant and Evan Mayo-Wilson in order to look at how to improve the way federal agencies rate the evidence base for social programs.
For a relatively small grant, I think the impact was high. At the outset, check out their overall website “Transparency of Research Underpinning Social Intervention Tiers,” or TRUST. They have been successful in promoting research transparency in the social intervention evidence ecosystem. A few examples:
The TOP Guidelines are now mentioned in federal clearinghouse guidelines (e.g., see Table 5), as well as by journals that supply evidence on intervention effectiveness to federal clearinghouses.
Research societies active in this ecosystem have created special interest groups on open science (e.g,. the Society for Prevention Research, or the Society for Research on Educational Effectiveness).
The grantees have led revisions to the TOP Guidelines based on TRUST Initiative activities: Sean is the chair and Evan is a member of the TOP Advisory Board (I’m a member as well).
Along with Lauren Supplee, they published an article reviewing evidentiary standards at 10 federal clearinghouses, and providing recommendations for how to improve. They have published a number of other articles available here.
My intuition is that even with all the progress to date, we could do even more here. For example, one perennial question for policymakers is, “Will it work here?”
Which is a reasonable question. Yes, an education program might have reduced high school dropouts in Seattle, but will it work in the Houston school district, with a population of largely poor, minority students (many of whom speak English as a second language)? We need better ways to figure out whether and how often evidence is transportable across different contexts and populations, and then give guidance to time-strapped policymakers across the country.
Community Building
BITSS
The Berkeley Initiative for Transparency in the Social Sciences (or BITSS) had its first annual meeting in December 2012. I recall briefly meeting Cari Tuna (who since launched Open Philanthropy with her husband Dustin). Other attendees included Richard Sedlmayr, Kevin Esterling, Brian Nosek, Leif Nelson, David Laitin, Josh Cohen, Jeremy Weinstein, Gabriel Lenz, Don Green, Colin Camerer, Ben Olken, Rachel Glennerster, Mark van der Laan, Maya Petersen, Kate Casey, Aprajit Mahajan, Temina Madon, Bryan Graham, Carson Christiano, and of course Ted Miguel. Not a bad group!

Over the years, we awarded BITSS several grants to help create more of an academic community supporting open science. Those grants included:
$204,729 in 2013 to collaborate with the Center for Open Science in training researchers to use the Open Science Framework software.
This grant included two summer institutes for PhD students, which eventually evolved into the flagship Research Transparency and Reproducibility Trainings (RT2), which continue today. It also allowed BITSS to create a manual of best practices in transparent social science research, write a chapter on transparency in the textbook Impact Evaluation in Practice, and contribute to the TOP guidelines.
$680,118 in 2015 to sponsor the SSMART competition (Social Science Meta-Analysis and Research Transparency) to identify and fund new papers/articles on meta-science in political science and economics, and a supplemental grant of $58,142 to support a couple of extra projects identified as worthy of funding. A lot of great meta-science papers were the result. A couple of examples:
Cristina Blanco-Perez and Abel Brodeur’s article showing that when health economics journals issued a statement about their willingness to publish null results, the number of positive and significant results went down by 18 percentage points.
Rachael Meager’s American Economic Review article developing new Bayesian hierarchical models for aggregating treatment effects across different studies. (Note: Rachael’s working paper was posted in late 2016, but the AER version didn’t come out until 2022!)
$408,719 in 2016 to fund outreach and training activities.
This grant partially supported three events (two international), ten on-demand workshops at academic and policy research organizations, two workshops at BITSS Annual Meetings, and two course runs of the BITSS Massive Online Open Course (MOOC), “Transparent and Open Social Science Research.” It allowed BITSS to significantly grow our BITSS Catalyst network, which today includes nearly 160 researchers in 30 countries who are estimated to trained over 20,000 additional researchers in transparency tools and methods. The Catalyst program is about to be re-booted with support from a relatively new BITSS donor (TWCF). Additionally, the grant supported engagement with over 80 journal editors and 200 science journalists on open science practices, and helped secure funding for a successful pilot of Registered Reports at the Journal of Development Economics. Finally, it allowed BITSS to disseminate several important research products, including the textbook Transparent and Reproducible Research, a paper on "Transparency, Reproducibility and the Credibility of Economics Research," and the State of Social Science (3S) Survey.
$590,571 in 2019 to help train researchers to comply with the American Economic Association policy on submitting data and code.
With the last grant there, BITSS also created the Social Science Reproduction Platform. One of the goals here was to eliciat information about replications performed as part of graduate education in political science, economics, etc. After all, some graduate students perform replication as part of a class on methods or data analysis, and it might be useful to know the results. As of now, the platform hosts information on 218 replications of 140 papers. Many of these replications have come from Abel Brodeur’s new Institute for Replication, an excellent effort that was launched after I left Arnold and hence never got the chance to support.
I think these replication efforts should be expanded ten-fold, including other disciplines. Indeed, whenever someone does a graduate degree that depends on analyzing data (whether it be economics or epidemiology), that student’s training ought to include replicating an existing study from its publicly available data. Hands-on data analysis like that is enormously useful (probably more so than toy exercises in an econometrics or statistics class), and the rest of the field should be able to benefit from seeing the replication success of numerous articles.
J-PAL
Around the 2016 timeframe, the American Economics Association was trying to popularize its registry for economics experiments, and J-PAL North America at MIT (long a significant Arnold grantee) wanted to pay for some substantial staff time to register and report the results of many existing RCTs, and as well as to train researchers on good transparency practices. I made a grant of $486,000 to J-PAL for that purpose, and was satisfied that it was reasonably successful.
Ecology/Evolution
In 2015, I got a proposal from Tim Parker of Whitman College, Shinichi Nakagawa of the Univ. of New South Wales, and Jessica Gurevitch of Stony Brook University, on “Developing Editorial and Funding Policies to Improve Inference in Evolutionary Biology and Ecology.” They pointed to evidence that those related fields were publishing too many false positives, unreplicable work, etc.
I made a grant of $77,962 for them to host a meeting with Center for Open Science, drawing leaders in the field from arounds the world. The key impacts of the eco-evo meeting were the creation of the Society for Open, Reliable, and Transparent Ecology and Evolutionary Biology (SORTEE), a list of tools and standards that journals could use for this research, and eventually the EcoEvoRxiv preprint service. It is also possible that the increased activity in ecology and evolutionary biology may have helped inspire AIMOS (Association for Interdisciplinary Meta-Research and Open Science), which has a significant presence in those fields.
A larger comment: There are of course many meetings where not much happens except that people present findings from their recent papers, other people ask some long questions that are really comments in disguise, and everyone goes home afterwards. The benefits are that people gain some knowledge, socialize with their colleagues, and hopefully think of new ideas for future studies.
But between this grant and the TOP Guidelines grant, I am convinced that meetings can do much more than the usual fare. That is, meetings can be one of the most effective ways to create future policy change. It all depends on whether the meeting taps into a current zeitgeist where there is an appetite for reform, and then sets out a meeting agenda that is sufficiently action-oriented (i.e., does it have a specific goal in mind towards which every attendee is expected to contribute?).
IV. Make It Rewarding
Chris Chambers and Registered Reports
As many readers know, registered reports are a new type of scholarly article in which scholars submit a proposed study to a journal; the journal conducts peer review and provisionally accepts the study (based on the proposed design, data collection, etc.); and then the scholars actually conduct the study. If all goes according to plan, the journal will then publish the finished product regardless of results.
While registered reports aren’t applicable to all research by any means, they could be particularly useful for confirmatory experiments, clinical trials, etc. For one thing, you get feedback from peer reviewers at a time when it is possible to change how you set up the experiment in the first place, rather than getting crucial feedback only when it’s too late.
For another thing, it can help prevent publication bias wherein editors and reviewers lean more towards publishing only positive and statistically significant results. Initial evidence on matched studies in psychology suggests that the rate of publishing positive results is cut by more than half:

That said, this isn’t a perfect comparison. Scholars who want to test risky hypotheses or who have the least confidence in a positive result (for whatever reason) might be the most likely to opt for a registered report pathway than for the usual pathway. Nonetheless, registered reports seemed intuitively obvious (for certain types of publications) as better than the usual.
The person most associated with registered reports is Chris Chambers of Cardiff University in the UK. He had helped organize an open letter signed by over 80 scientists (mostly UK) in 2013 (published in The Guardian) arguing for registered reports. The letter noted that since May of 2013, the neuroscience journal that Chambers edited (Cortex) had offered authors the possibility of publishing their work via a registered report. He had been doggedly working on the issue (the first medical journal started offering registered reports in 2017), but needed a grant to buy out his time at Cardiff University.
I awarded Chambers a grant of $240,000 from 2020 to 2024, with the idea that he could spend more time interacting with journal editors and advocating for registered reports. He partnered with the Center for Open Science on this work, and as of now, over 300 journals offer registered reports as a publishing option. He also worked to establish a website tracking how well journals and publishers are doing (Registered Reports Community Feedback) and a platform to offer peer review of registered reports, with the hope of taking control of the review process currently offered by journals and academic publishers (the Peer Community in Registered Reports platform).
Most recently, Nature (the most high-profile journal to date) signed on. As Chris Chambers announced on Twitter:
Beyond that, government agencies in both the UK and the US have recently recommended the use of registered reports.
The House of Commons Science, Innovation and Technology Committee released a report in April 2023 titled “Reproducibility and Research Integrity.” Paragraph 143 recommends that “publishers and funders should work together to offer a ‘registered report partnership model.’ Not only will this benefit researchers who will receive feedback on their research plans and guaranteed publication, but greater transparency in research methodologies will be achieved.”
The US Government Accountability Office released a report in July 2022 titled: “Research Reliability: Federal Actions Needed to Promote Stronger Research” (note: I was one of the outside experts consulted for this report). Page 24 recommends that government agencies try out a “registered reports pilot program” by partnering with journals to publish funded studies in a registered reports format.
We still have a ways to go, of course. I think that clinical trials in medicine should be published only as registered reports, for example. Unlike any other area of scientific research, clinical trials are already mostly required by law and by funder policies to be registered in advance of the trial’s launch. It would be relatively easy to change the journal submission process so that clinical trial articles are submitted before trial launch rather than after completion. As mentioned above, this would allow peer reviewers to make comments in time to alter the trial’s protocol (if necessary), and would force the journal to make a publication decision independent of the trial’s results.
Prizes
One way to make research practices rewarding is simply to offer rewards or prizes for the behaviors in question. This isn’t a permanent solution, but it could be a way to jump start the acceptance of new behavioral patterns in a given field. At least, so we thought.
Starting in the days when hardly anyone in social science had heard of preregistration, we sponsored a couple of prizes for preregistering studies. We thought this might raise the prominence of the issue, such that people would then start to think about preregistration on its own terms.
Preregistration Prize
One Christmas season nearly a decade ago, I was at a party at the Arnolds’ house chatting with John Arnold. He said to me, “What if we offered a $1,000 prize for anyone who preregisters their study and then gets it published?” I thought it sounded intriguing.
We ended up funding a grant for the Preregistration Challenge at the Center for Open Science that offered up to 1,000 awards of $1,000 each. A bit of the press at the time:

By now, this all may seem dated—no one needs to pay anyone $1,000 to preregister a study. But at the time, it seemed that too few people had even heard of preregistration (outside of clinical trials), and we thought it would help jump-start things (or at least draw attention) if we offered a reward. Did it work? Hard to say definitively, but Brian Nosek emailed these thoughts, which seem reasonable:
I perceive the Preregistration Challenge as playing a central role in consolidating interest, action, and understanding about the behavior. It is obviously very hard to pin down what adoption would have looked like without the Prereg Challenge. But it got plenty of awareness and engagement. We could never get around the self-selection effects of who decided to participate in the Challenge, but I bet that any investigation we did would show that (a) fields with strong participation in the challenge showed more acceleration after the challenge in adoption than neighboring fields, and (b) people that participated in the challenge continued to be more invested in prereg after the challenge than others who are as similar as possible in every other way.
An Election Research Prize
In 2016, I worked with Arthur “Skip” Lupia and Brendan Nyhan to create the Election Research Preacceptance Competition, namely, a contest to publish preregistered articles about the 2016 US election, using a traditional source of political science data (the American National Election Studies, or ANES). It wasn’t a huge grant—only $58,368. The idea was that participating scholars could get a $2,000 award for preregistering a study on 2016 ANES data before the 2016 election, and then submitting it for preacceptance as a registered report at a major political science journal.
A Washington Post interview at the time is here, and it includes this explanation of the grant’s origin:

The results? From an article on a similar initiative as to the German 2021 election:
Although more than 50 analysis plans were preregistered with a public registry, only two papers were eventually published in this competition (Enders and Scott 2019; Monogan 2020). The organizers (personal communication) suspect that the low number of publications was due to the fact that most preregistrations were submitted by early-career scholars who might have lacked experience on how to implement their ideas. In retrospect, the organizers concluded that the initiative could have benefited from early-career scholars receiving advice and mentoring from experienced researchers at the crucial stages of the process.
I asked Lupia and Nyhan for their thoughts, and one of them told me: “I think in general the competition struggled with the intersection of (a) people not being experienced with preregistration workflows (regardless of seniority) and (b) the difficulty of publishing ANES findings because they were seen as not novel enough and/or came out as nulls.”
V. Make It Required: Policy/Advocacy
In hindsight, perhaps we could have done more as to policy and advocacy. I only made a few such grants. That said, if I had been asked in 2014 or 2015 whether it made sense to do a ton of grantmaking on direct policies and mandates, I would have thought it was largely premature.
As seen above, for example, replication was very controversial at the time—trying to mandate replications would have gone nowhere. You can’t leapfrog the pyramid, at least not very successfully: even if you managed to persuade top policymakers to issue a top-down mandate, it would be circumvented, ignored, and shot down quickly if there was no low-level buy-in.
AllTrials
I saw the success that Ben Goldacre had with the AllTrials campaign in the UK and EU, and hoped to be able to replicate it in the United States. That is, I thought it made sense for patient advocacy groups and others to join forces to demand that clinical trials be rigorous and transparent, with no hidden results.
I sought out Trevor Butterworth to run an AllTrials campaign in the United States. I had seen Trevor in a well-spoken interview, and thought he would be perfect. I gave a grant of $1.5 million to Sense About Science USA (the parallel to Sense About Science UK, the group that technically ran the AllTrials campaign).
Trevor and his team launched an AllTrials campaign in the US, and over time were able to win endorsements from groups like the American Medical Association, the AARP, and the National Comprehensive Cancer Network. But the movement wasn’t just a campaign for organizational endorsements. A significant problem with clinical trial transparency is that lofty policy statements often ran aground on local capacities. That is, everyone in theory might agree with slogans like “all trials reported,” but what does that mean to the research manager at an academic hospital like MD Anderson who would need to spend significant time chasing down results and then reporting them publicly?
Trevor and the Sense About Science folks settled on a “train the trainer” strategy. To quote from one of their reports, “We want to identify, train and support people who are passionate about transparency in a way that enables them to: a) advocate effectively and b) train others in their community to become effective advocates.” The group then ran workshops at places like New York University and UC San Diego, among others. As well, they were working in 2017-18 with Memorial Sloan Kettering and New York’s Department of Health and Mental Hygiene on producing a patients’ guide to clinical trial transparency.
Along with the clinical trial work, Sense About Science USA launched a partnership with the American Statistical Association to provide statistical consulting to journalists, with the hope of improving statistical literacy and the overall quality of journalism.

As well, they ran many meetings and workshops aimed at journalists, including a workshop for biomedical journal editors at Springer Nature.

In the end, I included this grant as one about policy and advocacy, but it did more to engage in community training than to change policy.
Yale CRIT
The Yale Collaboration for Research Integrity and Transparency (CRIT) was borne out of conversations with Joe Ross, Amy Kapczynski, and Gregg Gonsolves at Yale, all of whom had done great work in pushing for clinical trial transparency. I awarded them a grant of over $2.8 million in 2016 in order to create the Yale CRIT project. The goals were to engage in research, advocacy, and litigation (if need be) to support more rigorous standards as to medical products (drugs, devices, procedures, etc.).
Active from 2016 to 2019, the collaboration brought together faculty and staff from across the Yale campus to pursue research, advocacy, and litigation to ensure that the clinical evidence on the safety and effectiveness of pharmaceuticals, medical devices, and other medical products is accurate, comprehensive, accessible, and reliable.
CRIT had a number of successes, including:
Litigating enforcement of the clinical trial registration and results reporting requirements as part of the Food and Drug Administration Amendments Act;
Filing Freedom of Information Act requests to secure access to information related to medical product approvals and safety;
Publishing key policy analyses and opinion articles on court secrecy, regulator data transparency efforts, and medical product evidentiary standards and authorization requirements;
Publishing a number of research studies, many in high impact medical journals, including articles on postmarket studies required by the FDA, on Medicare spending and potential savings on brand name drugs with available generic substitutes, on direct-to-consumer advertising and off-label claims, and on availability of experimental drugs; and,
Training a number of postgraduate and postdoctoral students and other staff who have gone on to take important roles in other organizations focused on regulatory integrity and transparency.
VI. Leftovers Are Often the Best
While at Arnold, I funded a number of initiatives that can’t be neatly categorized above, but that seem to have been high-impact in their own way.
How We Collect National Statistics
Around 2015, my friend Mike Chernew at Harvard approached me. He was working with the Committee on National Statistics (otherwise known as CNSTAT, pronounced See-In-Stat) at the National Academies of Science. That committee wanted to investigate how the federal government collects statistics in an era where fewer and fewer people respond to surveys, not to mention many other problems. Survey non-response is a huge issue—for example, the Consumer Expenditure Survey (used to help calculate everything from the inflation rate to national health spending) had a response rate of 86% in 1990, but by the end of 2018, that had dropped to 55%.
I awarded CNSTAT a grant of $828,349 in 2015 to fund what became two reports on how to improve federal data collection and statistics. After numerous meetings, CNSTAT released two reports in 2017.
The first, Innovations in Federal Statistics: Combining Data Sources While Protecting Privacy, was about the fact that while many important federal statistics (such as the unemployment rate) depend on surveys, the cost of doing a survey has been going up while the response rate has been going down. At the same time, administrative data has been growing, even though we often don’t know enough about the quality or sources of such data. Thus, the idea behind the report was to “foster a possible shift in federal statistical programs—from the current approach of providing users with the output from a single census, survey, or administrative records source to a new paradigm of combining data sources with state-of-the-art methods.”
The first report concluded that there are too many legal and administrative barriers to the use of administrative data, that federal statistical agencies should look at the benefits of using private data, that agencies should collaborate with academia and industry to develop new techniques to address confidentiality, that agencies should use new techniques to protect privacy, and that a “new entity” should try to enable “secure access to data for statistical purposes to enhance the quality of federal statistics.”
The second, Federal Statistics, Multiple Data Sources, and Privacy Protection: Next Steps, built on the first report by trying to assess new ways for combining diverse data resources (government or private sector). The report recommended that federal agencies redesign current methods so as to use multiple data sources, learn new ways to combine them, and figure out how to work with multiple organizations across the public and private sector. Moreover, agencies should look for ways to safeguard privacy even while combining datasets for research purposes. Finally, the panel recommended the creation of a new entity that would provide a secure environment for analyzing data, would coordinate the use and acquisition of data, and would work with federal agencies to identify research priorities.
The results? In 2018, the Office of Management and Budget cited CNSTAT’s work as “important work” on which “more research” would be needed “before the Federal Statistical System can adopt these techniques for the production of its key statistics.”
More importantly, these reports from CNSTAT laid the groundwork for redirecting CNSTAT’s approach and strategy towards a grand, forward-looking vision of national statistics—one that was labeled an integrated national data infrastructure. CNSTAT issued two reports in 2023 (funded by the National Science Foundation) that show how data generated on the activities of persons and enterprises are actually national resources, and showing that countries that mobilize those data to inform citizenry about the welfare of the country can build stronger economies and societies.
The first report was titled: “Toward a 21st Century National Data Infrastructure: Mobilizing Information for the Common Good.” The overarching theory was that the United States “needs a new 21st century national data infrastructure that blends data from multiple sources to improve the quality, timeliness, granularity, and usefulness of national statistics, facilitates more rigorous social and economic research, and supports evidence-based policymaking and program evaluations.” This new national data infrastructure should be prepared to include all sources of data (federal, state, private, etc.), and should have the following seven attributes:
1. Safeguards and advanced privacy-enhancing practices to minimize possible individual harm.
2. Statistical uses only, for common-good information, with statistical aggregates freely shared with all.
3. Mobilization of relevant digital data assets, blended in statistical aggregates to providing benefits to data holders, with societal benefits proportionate to possible costs and risks.
4. Reformed legal authorities protecting all parties’ interests.
5. Governance framework and standards effectively supporting operations.
6. Transparency to the public regarding analytical operations using the infrastructure.
7. State-of-the-art practices for access, statistical, coordination, and computational activities; continuously improved to efficiently create increasingly secure and useful information.
The second report was titled: “Toward a 21st Century National Data Infrastructure: Enhancing Survey Programs by Using Multiple Data Sources.” This report delved much deeper into the weeds of how you’d actually construct a national data infrastructure. For example, how do you probabilistically link administrative data to survey data in way that results in improved overall statistics? How should imputation be used for missing data elements? Who determines informed consent provisions for data drawn from many different sources? The report also discussed in detail numerous existing federal data sources, how they work, and how they could be improved (everything from Census datasets and Labor datasets to the June Area Survey that collects information on crops, grains, cattle, hogs, etc.).
In short, a national data infrastructure that combines administrative and survey data is the future of federal statistics. CNSTAT is a centrally important place where top experts on this issue come together to discuss the path forward, and I’m happy to have helped them along this path several years ago.
New Orleans Schools: Tulane and Blueprint
In 2012, the Arnold Foundation announced some $40 million in grants intended to transform the New Orleans school system. As the new Director of Research (my first and brief title), I started to think about how we could evaluate the success of promoting charter schools in New Orleans. It’s a difficult question—students aren’t randomly assigned to be in New Orleans versus elsewhere, and we couldn’t randomly assign New Orleans to adopt a new school system. Was there still going to be a way to compare New Orleans to anywhere else?
I solicited two large grants that launched new organizations/centers that continue to this day. Each organization ended up specializing in different ways of assessing school success.
First, I worked with the economist Douglas Harris on creating a new education research center at Tulane. It ended up being called the Education Research Alliance for New Orleans. We gave ERA three significant grants as operational support: $2.8 million in 2014 for the initial launch, and subsequent grants of $740,479 and $1.4 million.
The ERA team and their associated research fellows have published a wide range of analyses and evaluations of the New Orleans school system since the post-Katrina reforms, including evaluations of New Orleans students compared to similar students elsewhere in the state, the effect of transportation on school choice, the effect of education reform on adolescent crime, and much more.
The key to ERA’s success (as with research-practitioner partnerships more broadly) is developing strong relationships with local stakeholders who are willing to provide data, to provide input on study topics and the like, and to listen even when an evaluation shows uncomfortable results. Research and evaluation, in other words, aren’t successful when they come across as a bloodless and robotic analysis of numbers, but when they arise out of a human relationship of trust and good faith.
Second, I saw a Jan. 2, 2013 article about an MIT economist named Joshua Angrist and his then-recent interest in education research.

I reached out to Angrist, and had conference calls with him and Pathak about their ideas. Pathak had actually helped to design the “OneApp” system used in New Orleans to match families to schools, given all of the various preferences involved (e.g., neighborhood, family members, etc.).
Their new idea was to develop new methods for using all of the information on family and school preferences to create algorithms that would essentially find unseen randomization within the school choice process—that is, some students had a similar likelihood (given the school choice algorithm) of getting into a particular school, but then one of them would get in and the other wouldn’t (thus creating a mini-RCT between the two schools involved). Figure out each student’s propensity to get into each school, and each possible “mini-RCT” comparison, and you’d have large-scale information on which New Orleans schools were more successful.
But it was enormously complicated, and Angrist told me at the outset that it was still unknown if this would even be possible. Our initial grant was for a mere $71,524, to help support a graduate student.
Based on initial and promising results, I was able to get Angrist et al. a grant of $1,941,622 in 2018 to support their further work on using enrollment data to measure school quality in New York City and Denver (website here). Based on the findings from this project, the lab successfully raised $1 million in funding from the Walton Family Foundation to launch a related line of work with Greatschools.org, NYC, and Denver to remove racial bias in school quality measures (forthcoming in the AER, preprint here). Currently, the research team is planning an experiment with NYC and Greatschools.org to randomly offer families less-biased school quality measures to understand how they influence enrollment behaviors.
He and others ended up creating the School Effectiveness and Inequality Initiative, which then turned into Blueprint Labs. Blueprint advertises itself as using “data and economics to uncover the consequences of policy decisions and improve society.” The Arnold grant was the first major source of support that helped launch Blueprint’s education research efforts, which continue in full force today. The lab is currently in the process of launching a charter school research collaborative with support from the City Fund, Bloomberg Philanthropies, the Bill & Melinda Gates Foundation, and the Walton Family Foundation.
Besides being smart and accomplished, Josh is one of the most bad*** people I’ve ever known. For one, he initially dropped out of a graduate program to become an Israeli special forces paratrooper, as he casually mentioned when I visited his home. Not many prize-winning academics could say that.
And then there’s this:

Maybe some prize-winning academics could say that, but not many would.
Clinical Decision Support in Health Care
Back in the mid-2010s, there was a policy debate over whether clinical decision support systems could help improve how doctors make decisions. A specific example: some doctors recommend MRIs too often, leading to higher expense and unnecessary radiation for the patient. What if that doctor saw an electronic system that gave advice like, “This patient isn’t likely to benefit from an MRI”? Would the doctor listen to the system, or would he (it’s usually a “he” in this situation) demand an MRI regardless? Would we save money, and would patients be better off? Or the opposite?
Amy Finkelstein of MIT approached me in 2014 or 2015 with the thought that we had already given many millions to help launch J-PAL North America, with its focus on randomized trials on policies and programs, and maybe she shouldn’t ask for anything else. I told her that we were always open to new ideas.
So she pitched me on an idea of partnering with hospitals to do an RCT of a new policy that Medicare was about to roll out under the Protecting Access to Medicare Act of 2014—that is, requiring that high-cost scans couldn’t be reimbursed unless the hospital had a clinical decision support system in place. The idea was to randomize doctors to see the electronic recommendation (or not), and then see if they actually behaved differently.
We gave a grant of $1,156,095 to Amy’s project in 2015. This project had a major hiccup—the original hospital partner turned out to have failed the randomization (that is, they didn’t actually randomize any doctor to the control group!). But Amy’s team didn’t find out for a long time, because due to HIPAA regulations, they hadn’t been able to see the data (and see that no one was in the control group). She told me that a lesson learned was that when working with hospitals, place someone at the hospital who is allowed by HIPAA to see real-time data in order to check whether everything is actually going as planned.
With a new hospital partner, Amy and her colleagues published results in 2019: the clinical decision support system “reduced targeted imaging orders by a statistically significant 6%, however there was no statistically significant change in the total number of high-cost scans or of low-cost scans.” In other words, a potentially expensive national mandate to provide these recommendation systems might not make any meaningful difference to the actual use of high-cost scans.
The John Oliver Show
My experience consulting with the John Oliver show is hard to categorize, as it was thoroughly serendipitous and not part of a broader communications strategy. Indeed, I doubt I’d have been able to get scientific reproducibility on the John Oliver show if I had tried!
Take a step back: In 2016, I was bothered by how many journalists wrote breathless stories about the latest miracle cure from nutrition, cancer, etc., whereas the stories were based on studies in mice or rats. I decided to write up an article arguing that journalists should simply stop reporting on mice and rat studies. After all, even the best mice/rat studies might not pay off in humans, so why should we distract the public with the false hope of a cure for cancer or heart disease?
I shopped the piece around, but it was a little too dense for major publications, nor was it tied to any current event in the news. So, I just published it on the Arnold Foundation website (it’s still available here).
Shortly thereafter, I got word that a journalist from the John Oliver show wanted to talk to me. Her name was Liz Day (she is currently at the New York Times). When we chatted, it turned out that she had been searching for experts on mice/rats, and thought I was just such an expert. Not true, I assured her. I was simply someone who cared about the quality and relevance of medical studies, and of journalism reporting on them.
Fortunately, it didn’t matter that I wasn’t a mouse expert. She was actually producing a script for a story on scientific reproducibility, where mouse research was just one of the potential topics.
She and I ended up exchanging several thousand words of emails about a script for a then-upcoming show. I also provided her with potential interviews and video sources. Along with Meredith McPhail (who worked for me), I sent Liz Day many comments on the actual script regarding mouse studies, p-hacking, distinguishing “odds” from “probability,” oxytocin studies, nutrition studies, the FDA approval process, and most of all, how to define p-values.
For example, their original script at one point had said, “A p-value is a measure scientists use to identify real causal relationships from flukish coincidence.” Obviously, that’s not correct (technically, it IS correct to say that many scientists think this way, but that’s because they have no idea what a p-value actually means!).
In response, I rewrote the script, and added: “A p-value does NOT tell you the probability that the finding is due to chance. Rather, a p-value assumes that only chance is at work. That is, a p-value tells you, ‘If nothing other than chance were operating here, and if I collected data in the same way many times, what percentage of the time would the data look this extreme or more just by chance?’ Or to make that shorter, a p-value tells you, ‘If there is not a real effect here, how often would mere chance produce data where there seems to be an effect?’”
Her response: “Thank you, thank you, thank you again. We're crashing on this piece (we usually have much more time) but want to make sure we're being bulletproof with our accuracy (given that we're criticizing others' for sloppily talking about science).”
The episode came out in May 2016, and is available here. Among the Arnold grantees featured were Brian Nosek and Elizabeth Iorns (whose video I provided to the show). It was gratifying when, in 2017, a Columbia professor tweeted this:
I moderated a panel on Bayesian methods at an HHS conference in 2017. One of the people on the panel was Don Berry, who for many years was the head of biostatistics at MD Anderson, and who had helped design hundreds of clinical trials. In an email discussion prior to the conference, he told the other panelists to watch the John Oliver segment, and added: “I suspect that Stuart too played a role in the show. Oliver couldn’t have developed this level of sophistication without very, very competent advice.”
I responded to confirm that Don Berry’s suspicions were right, and asked how he had known? His response: “Thanks Stuart. You never told me you were involved. But I could count on the fingers of one hand the people who could be the brains behind this show, and you were the index finger.”
I’ll admit to a bit of self-aggrandizement in retelling these stories . . . but they are also a symptom of a broader problem. How routinely awful must science communication and journalism be, if multiple people were surprised that the John Oliver show could get even the most elementary facts about statistics correct? What would it say if every time anyone publicly mentioned gravity, physicists had to hold their breath to see whether someone said gravity increases with the square of distance, rather than being inversely proportional to distance squared? It shouldn’t be so difficult, or so surprising, for journalists to get basic issues correct.
On another note: How much difference did a John Oliver show episode make to any of the issues that I was working on? Hard to say. But as with much in philanthropy and communications/advocacy, the long-term impact of such efforts might far outstrip our ability to measure and quantify the impact.
Nutrition
After the demise of the Nutrition Science Initiative, I worked with my employee Meredith McPhail to launch two RFPs focused on nutrition. One was on rigorous ways to measure the effect of fat versus carbs, and the other was on innovative ways to measure what people actually eat.
We ended up funding an $11 million trial with David Ludwig of Harvard and David Allison of Indiana University, both highly reputable nutrition scholars. The trial was going to be the biggest-ever in-patient study of fat vs. carbs with a highly-controlled diet in a highly-controlled setting.
Sadly, the Covid pandemic interfered. The trial had completed 1/3 of the total planned enrollment when the pandemic lockdown hit during a cohort with the next 1/3 in residence. The trial became a nightmare. It was touch and go for everyone, modifying the protocol ad lib to prioritize safety. For example, the trialists couldn’t just send people to their homes around the country, as this would have involved exposure risk during travel. Yet bringing in staff to oversee the trial and prepare food itself was risky. The trialists decided to end the trial early, resulting in an underpowered trial (2/3 expected total) with quality-control issues involving half the completed participants.
Even so, the trialists plan to make the best of it. Their first major paper was published in Diabetes Care, on how glucose metrics respond when people switch from a low-carb to high-carb diet. And they hope to produce a major paper on the main question later this year.
Causal Inference
Several years ago, I noticed that the Atlantic Society for Causal Inference featured a ton of my academic friends and colleagues who were thinking about how best to estimate the causal impact of policies, treatments, programs, etc. In my experience, this is by far the most amazingly cool academic society: Top statisticians like Brad Carlin, Mike Jordan, and Jennifer Hill formed a band called the Imposteriors that plays cover songs at society events—and they were actually good. Not just “good” on a charitable scale where you think “a 10 for academics but a 2 in the real world.” They are actually good. Better than a lot of live bands.
But the society was scraping by from year to year, essentially having to start up from scratch every time they met. I gave them a grant that at a mere $81,579 allowed them to have a more solid base to coordinate resources, and to rename it to the Society for Causal Inference so that it didn’t seem as geographically limited.
I don’t know that this grant had a major impact on anything but the Society for Causal Inference itself, but I do think there should be a place in philanthropy for using relatively small grants to help modernize or refashion existing institutions. Too many non-profits get stuck in the past, and it can be incredibly hard to look for a minor grant for operational costs to redo a website, hire a part-time executive assistant, etc. A relatively small grant can help them rebrand so as to have greater reach and impact.
Conclusion
What started out as a short essay ended up being much longer than I expected. But I hope there are many ideas throughout about how to promote good science and do high-impact philanthropy.
One grantee wrote to me:
“That grant was a real accelerator. The flexibility (which flows from trust, and confidence, in a funder) was critical in being able to grow, and do good work. It also helped set my expectations high around funders being facilitative rather than obstructive (possibly too high…). I think clueful funding is critical, I have seen funders hold projects and people back, not by whether they gave money, but how they gave it, and monitored work afterwards.”
To me, that captures the best of what philanthropy can do. Find great people, empower them with additional capital, and get out of their way.
By contrast, government funders make grants according to official criteria and procedures. Private philanthropy often acts the same way. As a result, there aren’t enough opportunities for innovative scientists or metascientists to get funding for their best ideas.
My own success as a metascience VC would have been far less if I had been forced to project a high expected-value for each grant. Indeed, such a requirement would have literally ruled out many of the highest-impact grants that I made (or else I would have been forced to produce bullshit projections).
The paradox is that the highest-impact work often cannot be predicted reliably in advance. Which isn’t that surprising. As in finance, the predictable activities that might lead to high impact are essentially priced into the market, because people and often entire organizations will already be working on those activities (often too much so!).
If you want to make additional impact beyond that, you’re left with activities that can’t be perfectly predicted and planned several years in advance, and that require some insight beyond what most peer reviewers would endorse.
What’s the solution? You have to rely on someone’s instinct or “nose” for smelling out ideas where the only articulable rationale is, “These people seem great and they’ll probably think of something good to do,” or “Not sure why, but this idea seems like it could be really promising.” In a way, it’s like riding a bicycle: it depends heavily on tacit and unarticulable knowledge, and if you tried to put everything in writing in advance, you would just make things worse.
Both public and private funders should look for more ways for talented program officers to hand out money (with few or no strings attached) to people and areas that they feel are promising. That sort of grantmaking might never be 100% when it comes to public funds at NIH or NSF, but maybe it could be 20%, just as a start. I suspect the results would be better than today, if only by increasing variance.
UPDATE:
As long as this essay is, it is nowhere near being comprehensive as to all the work I did at LJAF/AV! I advised the foundation’s Board (the Arnolds and the current President) on hundreds of millions in other grants that I didn’t myself originate as part of the metascience work, and this essay is only about the latter category of work. If I wrote an essay about the former, I would have talked about our funding of Vinay Prasad’s work on medical reversals, or our funding of folks to help start the White House Social and Behavioral Science Team in 2013, or our large grant to help start up J-PAL North America (for whom I reviewed dozens of outside research proposals), or our early funding of Raj Chetty’s Equality of Opportunity project, or helping David Yokum write a proposal to start up the Lab@DC, and much more.
SECOND UPDATE:
I managed to forget no fewer than two major grants.
Access to Justice Lab at Harvard
I can’t remember where I first came across Jim Greiner, a Harvard Law professor with a PhD in statistics. It may well have been this GiveWell interview, although I also remember seeing a news article at the time (which I currently cannot find).
Anyway, I was impressed with Greiner’s attempt to combine both legal and statistical expertise in order to conduct randomized trials in the legal system (both criminal and civil). As he later wrote in a Science article, “many questions fundamental to legal practice and those it affects, such as allocation of attorney services, bail decisions, and use of mandatory mediation, could and should be informed by a rigorous evidentiary foundation.”
Yet currently, there is little or no such evidence. We just rely on the expert opinions of lawyers. Law is arguably in the same position as medicine was prior to the mid-20th century—it often recommends actions that might deeply affect someone’s life, with no basis other than subjective opinion. Randomized trials would be a quantum leap forward. Greiner thus saw his life’s mission as getting the legal system to do RCTs anywhere and everywhere.
I reached out to Greiner, and we worked together on developing a proposal. Long story short, I pitched a major grant to the Arnolds, and in 2016, we awarded Greiner $5,422,849 to launch the Access to Justice Lab at Harvard (abbreviated A2J).
The A2J Lab formally launched on July 1, 2016. In the first two years, it launched 4 major RCTs in the legal system (one on debt relief, one on pretrial risk assessment, one on guardianship materials, and another one on debt collection). It had at least 10 other RCTs in active development, and was an inspiration elsewhere (as reported at the time, UK foundations planned to create a legal center “modeled explicitly and publicly” on the A2J Lab). And as of now, it has 18 RCTs in the field in 18 states, with 8 further projects in development.
I couldn’t be happier about this. There should be many more philanthropic and government efforts to do RCTs in the legal system, and Greiner’s effort is hopefully a foot in the door towards that end.
PORTAL
As in many cases above, I can’t remember how exactly I came across the relevant folks, but I helped launch the Program on Regulation, Therapeutics, and Law (PORTAL) Biomarker Research Center at Harvard Medical School.
Sometime in the 2014-15 timeframe, I came across Aaron Kesselheim at Harvard, probably via the incipient health policy work that the Arnold Foundation was doing at the time. He pitched me on a major effort that would focus on drug and device regulation by the FDA, particularly on the problem of biomarkers.
The FDA often makes decisions based on biomarkers and surrogate outcomes— for simplicity’s sake, think of a drug that improves something other than actual mortality or quality of life, but instead is just improving something like a cholesterol reading, or a blood pressure measurement, or the size of a tumor.
These sorts of outcomes are a bit treacherous. For example, if you’re a cancer patient, there’s no reason to care that your tumor size temporarily shrunk if you in fact end up dying at the same time. And it is surprisingly common for biomarkers that seem perfectly logical to end up not having any effect on lifespan or quality of life.
Even cholesterol! There are numerous cases where a drug that lowered cholesterol didn’t improve heart disease at all, and even a famous diet study where lowering cholesterol caused substantially more deaths.

Kesselheim proposed that a new effort at Harvard (with other personnel including Jerry Avorn, Jessica Franklin, Vishal Vaidya, Jing Luo, and Spencer Hey) should focus on this problem by doing systematic reviews and meta-analyses of biomarker testing, by publishing policy analyses and engaging with policymakers at FDA and elsewhere, hosting conferences, providing advice to clinical trialists on ethical consent, and more.
We ended up making a $1,968,553 grant to help establish the PORTAL center at Harvard, which formally launched in 2017. In the first couple of years, it hosted several conferences, published dozens of papers, and more. Since then, it has had many other financial supporters, and since money is fungible, it’s hard to know what to attribute to any one grant. But I do know that Kesselheim told me the initial grant “definitely helped launch PORTAL!,” so in a way that helped contribute to all of the subsequent activities.
THIRD UPDATE:
I managed to forget yet another grant. Not a major one, but it was still fun. I can’t remember how I came across the filmmaker Dakin Henderson, but I somehow persuaded the Arnolds to give him a small grant (I think it was on the order of $20k) to make a short documentary about scientific reproducibility. It featured many other Arnold grantees, and aired on PBS NOVA in 2017 (video here).
How much did a PBS documentary matter? Hard to say. I do think this sort of thing helps attract public attention and support.
Brilliant piece. I've never, as a working scientist, understood the whole resistance to replication 'mindset' (a phrase I use colloquially 😉, given recent controversies). The greatest thrill you can have is that someone else gets the same result as you did: it means you have either discovered something about the world that is independent of you, or you've both been confounded by the same artifact. One hopes for the former, but it can be the latter. It also means you've potentially discovered something that others regard as worth probing further. Amazing and wonderful venture: congratulations.
What a run!
Maybe for a future post... how would you train or advise a group of new metascience VCs? What advice would you give?